3: Metadata
3.1 Introduction
3.1.1 Metadata is structured data that provides intelligence in support of more efficient operations on resources, such as preservation, reformatting, analysis, discovery and use. It operates at its best in a networked environment, but is still a necessity in any digital storage and preservation environment. Metadata instructs end-users (people and computerised programmes) about how the data are to be interpreted. Metadata is vital to the understanding, coherence and successful functioning of each and every encounter with the archived object at any point in its lifecycle and with any objects associated with or derived from it.
3.1.2 It will be helpful to think about metadata in functional terms as “schematized statements about resources: schematized because machine understandable, [as well as human readable]; statements because they involve a claim about the resource by a particular agent; resource because any identifiable object may have metadata associated with it” (Dempsey 2005). Such schematized (or encoded) statements (also referred to as metadata ‘instances’) may be very simple, a single Uniform Resource Identifier (URI), within a single pair of angle brackets < > as a container or wrapper and a namespace. Typically they may become highly evolved and modular, comprising many containers within containers, wrappers within wrappers, each drawing on a range of namespace schemas, and assembled at different stages of a workflow and over an extended period of time. It would be most unusual for one person to create in one session a definitive, complete metadata instance for any given digital object that stands for all time.
3.1.3 Regardless of how many versions of an audio file may be created over time, all significant properties of the file that has archival status must remain unchanged. This same principle applies to any metadata embedded in the object (see section 3.1.4 below). However, data about any object are changeable over time: new information is discovered, opinions and terminology change, contributors die and rights expire or are re-negotiated. It is therefore often advisable to keep audio files and all or some metadata files separate, establish appropriate links between them, and update the metadata as information and resources become available. Editing the metadata within a file is possible, though cumbersome, and does not scale up as an appropriate approach for larger collections. Consequently, the extent to which data is embedded in the files as well as in separate data management system will be determined by the size of the collection, the sophistication of the particular data management system, and the capabilities of the archive personnel.
3.1.4 Metadata may be integrated with the audio files and is in fact suggested as an acceptable solution for a small scale approach to digital storage systems (see section 7.4 Basic Metadata). The Broadcast Wave Format (BWF) standardized by the European Broadcasting Union (EBU), is an example of such audio metadata integration, which allows the storage of a limited number of descriptive data within the .wav file (see section 2.8 File Formats). One advantage of storing the metadata within the file is that it removes the risk of losing the link between metadata and the digital audio. The BWF format supports the acquisition of process metadata and many of the tools associated with that format can acquire the data and populate the appropriate part of the BEXT (broadcast extension) chunk.The metadata might therefore include coding history, which is loosely defined in the BWF standard, and allows the documentation of the processes that lead to the creation of the digital audio object. This shares similarities with the event entity in PREMIS (see 3.5.2 ,3.7.3 and Fig.1 ).When digitizing from analogue sources the BEXT chunk can also be used to store qualitative information about the audio content. When creating a digital object from a digital source, such as DAT or CD, the BEXT chunk can be used to record errors that might have occurred in the encoding process.
A=<ANALOGUE> Information about the analogue sound signal path A=<PCM> Information about the digital sound signal path F=<48000, 441000, etc.> Sampling frequency [Hz] W=<16, 18, 20, 22, 24, etc.> Word length [bits] M=<mono, stereo, 2-channel> Mode T=<free ASCII-text string> Text for comments Coding History Field: BWF (http://www.ebu.ch/CMSimages/en/tec_text_r98-1999_tcm6-4709.pdf) ,> A=ANALOGUE, M=Stereo,T=Studer A820;SN1345;19.05;Reel;AMPEX 406 A=PCM, F=48000,W=24, M=Stereo,T=Apogee PSX-100;SN1516;RME DIGI96/8 Pro A=PCM, F=48000,W=24, M=Stereo,T=WAV A=PCM, F=48000,W=24, M=stereo,T=2006-02-20 File Parser brand name A=PCM, F=48000,W=24, M=stereo,T=File Converter brand name 2006 -02-20; 08:10:02
Fig. 1 National Library of Australia’s interpretation of the coding history of an original reel converted to BWF using database and automated systems.
3.1.5 The Library of Congress has been working on formalising and expanding the various data chunks in the BWF file. Embedded Metadata and Identifiers for Digital Audio Files and Objects: Recommendations for WAVE and BWF Files Today is their latest draft available for comment at http://home.comcast.net/~cfle/AVdocs/Embed_Audio_081031.doc. AES X098C is another development in the documentation of process and digital provenance metadata.
3.1.6 There are however, many advantages to maintaining metadata and content separately, by employing, for instance a framework standard such as METS (Metadata Encoding and Transmission Standard see section 3.8 Structural Metadata – METS). Updating, maintaining and correcting metadata is much simpler in a separate metadata repository. Expanding the metadata fields so as to incorporate new requirements or information is only possible in an extensible, and separate, system, and creating a variety of new ways of sharing the information requires a separate repository to create metadata the can be used by those systems. For larger collections the burden of maintaining metadata only in the headers of the BWF file would be unsustainable. MPEG-7 requires that audio content and descriptive metadata are separated, though descriptions can be multiplexed with the content as alternating data segments.
3.1.7 It is of course possible to wrap a BWF file with a much more informed metadata, and providing the information kept in BWF is fixed and limited, this approach has the advantage of both approaches. Another example of integration is the tag metadata that needs to be present in access files so that a user may verify that the object downloaded or being streamed is the object that was sought and selected. ID3, the tag used in MP3 files to describe content information which is readily interpreted by most players, allows a minimum set of descriptive metadata. And METS itself has been investigated as a possible container for packaging metadata and content together, though the potential size of such documents suggests this may not be a viable option to pursue.
3.1.8 A general solution for separating the metadata from the contents (possibly with redundancy if the contents includes some metadata) is emerging from work being undertaken in several universities in liaison with major industrial suppliers such as SUN Microsystems, Hewlett-Packard and IBM. The concept is to always store the representation of one resource as two bundled files: one including the ‘contents’ and the other including the metadata associated to that content. The second file includes:
3.1.8.1 The list of identifiers according to all the involved rationales. It is in fact a series of “aliases” pertaining to the URN and the local representation of the resource (URL).
3.1.8.2 The technical metadata (bits per sample / sampling rate; accurate format definition; possibly the associated ontology).
3.1.8.3 The factual metadata (GPS coordinates / Universal time code / Serial number of the equipment / Operator / ...).
3.1.8.4 The semantic metadata.
3.1.9 In summary, most systems will adopt a practical approach that allows metadata to be both embedded within files and maintained separately, establishing priorities (i.e. which is the primary source of information) and protocols (rules for maintaining the data) to ensure the integrity of the resource.
3.2 Production
3.2.1 The rest of this chapter assumes that in most cases the audio files and the metadata files will be created and managed separately. In which case, metadata production involves logistics – moving information, materials and services through a network cost-effectively. However, a small scale collection, or an archive in earlier stages of development, may find advantages in embedding metadata in BWF and selectively populating a subset of the information described below. If done carefully, and with due understanding of the standards and schemas discussed in this chapter, such an approach is sustainable and will be migrate- able to a fully implemented system as described below. Though a decision can be made by an archive to embed all or some metadata within the file headers, or to manage only some data separately, the information within this chapter will still inform this approach. (See also Chapter 7 Small Scale Approaches to Digital Storage Systems).
3.2.2 Until recently the producers of information about recordings either worked in a cataloguing team or in a technical team and their outputs seldom converged. Networked spaces blur historic demarcations. Needless to say, the embodiment of logistics in a successful workflow also requires the involvement of people who understand the workings and connectivity of networked spaces. Metadata production therefore involves close collaboration between audio technicians, Information Technology (IT) and subject specialists. It also requires attentive management working to a clearly stated strategy that can ensure workflows are sustainable and adaptable to the fast-evolving technologies and applications associated with metadata production.
3.2.3 Metadata is like interest - it accrues over time. If thorough, consistent metadata has been created, it is possible to predict this asset being used in an almost infinite number of new ways to meet the needs of many types of user, for multi-versioning, and for data mining. But the resources and intellectual and technical design issues involved in metadata development and management are not trivial. For example, some key issues that must be addressed by managers of any metadata system include:
3.2.3.1 Identifying which metadata schema or extension schemas should be applied in order to best meet the needs of the production teams, the repository itself and the users;
3.2.3.2 Deciding which aspects of metadata are essential for what they wish to achieve, and how granular they need each type of metadata to be. As metadata is produced for the long-term there will likely always be a trade-off between the costs of developing and managing metadata to meet current needs, and creating sufficient metadata that will serve future, perhaps unanticipated demands;
3.2.3.3 Ensuring that the metadata schemas being applied are the most current versions.
3.2.3.4 Interoperability is another factor; in the digital age, no archive is an island. In order to send content to another archive or agency successfully, there will need to be commonality of structure and syntax. This is the principle behind METS and BWF.
3.2.4 A measure of complexity is to be expected in a networked environment where responsibility for the successful management of data files is shared. Such complexity is only unmanageable, however, if we cling to old ways of working that evolved in the early days of computers in libraries and archives –before the Web and XML. As Richard Feynman said of his own discipline, physics, 'you cannot expect old designs to work in new circumstances'. A new general set of system requirements and a measure of cultural change are needed. These in turn will permit viable metadata infrastructures to evolve for audiovisual archives.
3.3 Infrastructure
3.3.1 We do not need a ‘discographic’ metadata standard: a domain-specific solution will be an unworkable constraint.We need a metadata infrastructure that has a number of core components shared with other domains, each of which may allow local variations (e.g. in the form of extension schema) that are applicable to the work of any particular audiovisual archive. Here are some of the essential qualities that will help to define the structural and functional requirements:
3.3.1.1 Versatility: For the metadata itself, the system must be capable of ingesting, merging, indexing, enhancing, and presenting to the user, metadata from a variety of sources describing a variety of objects, It must also be able to define logical and physical structures, where the logical structure represents intellectual entities, such as collections and works, while the physical structure represents the physical media (or carriers) which constitute the source for the digitized objects. The system must not be tied to one particular metadata schema: it must be possible to mix schema in application profiles (see 3.9.8) suited to the archive’s particular needs though without compromising interoperability. The challenge is to build a system that can accommodate such diversity without needless complication for low threshold users, nor prevent more complex activities for those requiring more room for manoeuvre.
3.3.1.2 Extensibility: Able to accommodate a broad range of subjects, document types (e.g. image and text files) and business entities (e.g. user authentication, usage licenses, acquisition policies, etc.). Allow for extensions to be developed and applied or ignored altogether without breaking the whole, in other words be hospitable to experimentation: implementing metadata solutions remains an immature science.
3.3.1.3 Sustainability: Capable of migration, cost-effective to maintain, usable, relevant and fit for purpose over time.
3.3.1.4 Modularity: The systems used to create or ingest metadata, and merge, index and export it should be modular in nature so that it is possible to replace a component that performs a specific function with a different component, without breaking the whole.
3.3.1.5 Granularity: Metadata must be of a sufficient granularity to support all intended uses. Metadata can easily be insufficiently granular, while it would be the rare case where metadata would be too granular to support a given purpose.
3.3.1.6 Liquidity: Write once, use many times. Liquidity will make digital objects and representations of those objects self-documenting across time, the metadata will work harder for the archive in many networked spaces and provide high returns for the original investments of time and money.
3.3.1.7 Openness and transparency: Supports interoperability with other systems. To facilitate requirements such as extensibility, the standards, protocols, and software incorporated should be as open and transparent as possible.
3.3.1.8 Relational (hierarchy/sequence/provenance): Must express parent- child relationships, correct sequencing, e.g. the scenes of a dramatic performance, and derivation. For digitized items, be able to support accurate mappings and instantiations of original carriers and their intellectual content to files. This helps ensure the authenticity of the archived object (Tennant 2004).
3.3.2 This recipe for diversity is itself a form of openness. If an open W3C (World Wide Web Consortium) standard, such as Extensible Markup Language (XML), a widely adopted mark-up language, is selected then this will not prevent particular implementations from including a mixture of standards such as Material Exchange Format (MXF) and Microsoft’s Advanced Authoring Format (AAF) interchange formats.
3.3.3 Although MXF is an open standard, in practice the inclusion of metadata in the MXF is commonly made in a proprietary way. MXF has further advantages for the broadcast industry because it can be used to professionally stream content whereas other wrappers only support downloading the complete file. The use of MXF for wrapping contents and metadata would only be acceptable for archiving after the replacement of any metadata represented in proprietary formats by open metadata formats.
3.3.4 So much has been written and said about XML that it would be easy to regard it as a panacea. XML is not a solution in itself but a way of approaching content organisation and re-use, its immense power harnessed through combining it with an impressive array of associated tools and technologies that continue to be developed in the interests of economical re-use and repurposing of data. As such, XML has become the de-facto standard for representing metadata descriptions of resources on the Internet. A decade of euphoria about XML is now matched by the means to handle it thanks to the development of many open source and commercial XML editing tools (See 3.6.2).
3.3.5 Although reference is made in this chapter to specific metadata formats that are in use today, or that promise to be useful in the future, these are not meant to be prescriptive. By observing those key qualities in section 3.3.1 and maintaining explicit, comprehensive and discrete records of all technical details, data creation and policy changes, including dates and responsibility, future migrations and translations will not require substantial changes to the underlying infrastructure. A robust metadata infrastructure should be able to accommodate new metadata formats by creating or applying tools specific to that format, such as crosswalks, or algorithms for translating metadata from one encoding scheme to another in an effective and accurate manner. A number of crosswalks already exist for formats such as MARC, MODS, MPEG-7 Path, SMPTE and Dublin Core. Besides using crosswalks to move metadata from one format to another, they can also be used to merge two or more different metadata formats into a third, or into a set of searchable indexes. Given an appropriate container/transfer format, such as METS, virtually any metadata format such as MARC-XML, Dublin Core, MODS, SMPTE (etc), can be accommodated. Moreover, this open infrastructure will enable archives to absorb catalogue records from their legacy systems in part or in whole while offering new services based on them, such as making the metadata available for harvesting – see OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting).
3.4 Design - Ontologies
3.4.1 Having satisfied those top-level requirements, a viable metadata design, in all its detail, will take its shape from an information model or ontology1. Several ontologies may be relevant depending on the number of operations to be undertaken. CIDOC’s CRM (Conceptual Reference Model http://cidoc.ics.forth.gr/) is recommended for the cultural heritage sector (museums, libraries and archives); FRBR (Functional Requirements for Bibliographic Records http://www.loc.gov/cds/downloads/FRBR.PDF) will be appropriate for an archive consisting mainly of recorded performances of musical or literary works, its influence enhanced by close association with RDA (Resource Description and Access) and DCMI (Dublin Core Metadata Initiative). COA (Contextual Ontology Architecture http://www.rightscom.com/Portals/0/Formal_Ontology_for_Media_Rights_Tran...) will be fit for purpose if rights management is paramount, as will the Motion Picture Experts Group rights management standard, MPEG-21.RDF (Resource Description Framework http://www.w3.org/RDF/), a versatile and relatively light-weight specification, should be a component especially where Web resources are being created from the archival repository: this in turn admits popular applications such as RSS (Really Simple Syndication) for information feeds (syndication). Other suitable candidates that improve the machine handling and interpretation of the metadata may be found in the emerging ‘family’ of ontologies created using OWL (Web Ontology Language). The definition of ontologies and the reading of ontologies expressed in OWL can easily be made using “Protégé”, an open tool of the Stanford University: http://protege.stanford.edu/. OWL can be used from a simple definition of terms up to a complex object oriented modelling.
1 W3C definition: An ontology defines the terms used to describe and represent an area of knowledge. Ontologies are used by people, databases, and applications that need to share domain information (a domain is just a specific subject area or area of knowledge, like medicine, tool manufacturing, real estate, automobile repair, financial management, etc.). Ontologies include computer-usable definitions of basic concepts in the domain and the relationships among them (note that here and throughout this document, definition is not used in the technical sense understood by logicians). They encode knowledge in a domain and also knowledge that spans domains. In this way, they make that knowledge reusable.
3.5 Design – Element sets
3.5.1 A metadata element set comes next in the overall design. Here three main categories or groupings of metadata are commonly described:
3.5.1.1 Descriptive Metadata, which is used in the discovery and identification of an object.
3.5.1.2 Structural Metadata, which is used to display and navigate a particular object for a user and includes the information on the internal organization of that object, such as the intended sequence of events and relationships with other objects, such as images or interview transcripts.
3.5.1.3 Administrative Metadata, which represents the management information for the object (such as the namespaces that authorise the metadata itself), dates on which the object was created or modified, technical metadata (its validated content file format, duration, sampling rate, etc.), rights and licensing information. This category includes data essential to preservation.
3.5.2 All three categories, descriptive, structural and administrative, must be present regardless of the operation to be supported, though different sub-sets of the data may exist in any file or instantiation. So, if the metadata supports preservation – “information that supports and documents the digital preservation process” (PREMIS) – then it will be rich in data about the provenance of the object, its authenticity and the actions performed on it. If it supports discovery then some or all of the preservation metadata will be useful to the end user (i.e. as a guarantor of authenticity) though it will be more important to elaborate and emphasise the descriptive, structural and licensing data and provide the means for transforming the raw metadata into intuitive displays or in readiness for harvesting or interaction by networked external users. Needless to say, an item that cannot be found can neither be preserved nor listened to so the more inclusive the metadata, with regard to these operations, the better.
3.5.3 Each of those three groupings of metadata may be compiled separately: administrative (technical) metadata as a by-product of mass-digitization; descriptive metadata derived from a legacy database export; rights metadata as clearances are completed and licenses signed. However, the results of these various compilations need to be brought together and maintained in a single metadata instance or set of linked files together with the appropriate statements relating to preservation. It will be essential to relate all these pieces of metadata to a schema or DTD (Document Type Definition) otherwise the metadata will remain just a ‘blob’, an accumulation of data that is legible for humans but unintelligible for machines.
3.6 Design – Encoding and Schemas
3.6.1 In the same way that audio signals are encoded to a WAV file, which has a published specification, the element set will need to be encoded: XML, perhaps combined with RDF, is the recommendation stated above. This specification will be declared in the first line of any metadata instance <?xml version=“1.0” encoding=“UTF-8” ?>. This by itself provides little intelligence: it is like telling the listener that the page of the CD booklet they are reading is made of paper and is to be held in a certain way. What comes next will provide intelligence (remember, to machines as well as people) about the predictable patterns and semantics of data to be encountered in the rest of the file. The rest of the metadata file header consists typically of a sequence of namespaces for other standards and schema (usually referred to as ‘extension schema’) invoked by the design.
<mets:mets xmlns:mets=“http://www.loc.gov/standards/mets/ ” xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance ” xmlns:dc=“http://dublincore.org/documents/dces/ ” xmlns:xlink=“http://www.w3.org/TR/xlink/ ” xmlns:dcterms=“http://dublincore.org/documents/dcmi-terms/ ” xmlns:dcmitype=“http://purl.org/dc/dcmitype ” xmlns:tel=“http://www.theeuropeanlibrary.org/metadatahandbook/telterms.html ” xmlns:mods=“http://www.loc.gov/standards/mods/ ” xmlns:cld=“http://www.ukoln.ac.uk/metadata/rslp/schema/ ” xmlns:blap=“http://labs.bl.uk/metadata/blap/terms.html ” xmlns:marcrel=“http://id.loc.gov/vocabulary/relators.html ” xmlns:rdf=“http://www.w3.org/1999/02/22-rdf-syntax-ns#type ” xmlns:blapsi=“http://sounds.bl.uk/blapsi.xml ” xmlns:namespace-prefix=“blapsi”>
Fig 2: Set of namespaces employed in the British Library METS profile for sound recordings
3.6.2 Such intelligent specifications, in XML, are called XML schema, the successor to DTD. DTDs are still commonly encountered on account of the relative ease of their compilation. The schema will reside in a file with the extension .xsd (XML Schema Definition) and will have its own namespace to which other operations and implementations can refer. Schemas require expertise to compile. Fortunately open source tools are available that enable a computer to infer a schema from a well-formed XML file. Tools are also available to convert xml into other formats, such as .pdf or .rtf (Word) documents into XML. The schema may also incorporate the idealised means for displaying the data as an XSLT file. Schema (and namespaces) for descriptive metadata will be covered in more detail in 3.9 Descriptive Metadata – Application Profiles, Dublin Core (DC) below.
3.6.3 To summarise the above relationships, an XML Schema or DTD describes an XML structure that marks up textual content in the format of an XML encoded file. The file (or instance) will contain one or more namespaces representing the extensionr schema that further qualify the XML structure to be deployed.
3.7 Administrative Metadata – Preservation Metadata
3.7.1 The information described in this section is part of the administrative metadata grouping. It resembles the header information in the audio file and encodes the necessary operating information. In this way the computer system recognises the file and how it is to be used by first associating the file extension with a particular type of software, and reading the coded information in the file header. This information must also be referenced in a separate file to facilitate management and aid in future access because file extensions are at best ambiguous indicators of the functionality of the file. The fields which describe this explicit information, including type and version, can be automatically acquired from the headers of the file and used to populate the fields of the metadata management system. If an operating system, now or in the future, does not include the ability to play a .wav file or read an .xml instance for example, then the software will be unable to recognise the file extension and will not be able to access the file or determine its type. By making this information explicit in a metadata record, we make it possible for future users to use the preservation management data and decode the information data. The standards being developed in AES-X098B which will be released by the Audio Engineering Society as AES57 “AES standard for audio metadata – audio object structures for preservation and restoration” codify this aspiration.
3.7.2 Format registries now exist, though are still under development, that will help to categorise and validate file formats as a pre-ingest task: PRONOM (online technical registry, including file formats, maintained by TNA (The National Archives, UK), which can be used in conjunction with another TNA tool DROID (Digital Record Object Identification – that performs automated batch identification of file formats and outputs metadata). From the U.S, Harvard University GDFR (Global Digital Format Registry) and JHOVE (JSTOR/Harvard Object Validation Environment identification, validation, and characterization of digital objects) offer comparable services in support of preservation metadata compilation. Accurate information about the file format is the key to successful long-term preservation.
3.7.3 Most important is that all aspects of preservation and transfer relating to audio files, including all technical parameters are carefully assessed and kept. This includes all subsequent measures carried out to safeguard the audio document in the course of its lifetime. Though much of the metadata discussed here can be safely populated at a later date the record of the creation of the digital audio file, and any changes to its content, must be created at the time the event occurs. This history metadata tracks the integrity of the audio item and, if using the BWF format, can be recorded as part of the file as coding history in the BEXT chunk. This information is a vital part of the PREMIS preservation metadata recommendations. Experience shows that computers are capable of producing copious amounts of technical data from the digitization process. This may need to be distilled in the metadata that is to be kept. Useful element sets are proposed in the interim set AudioMD (http://www.loc.gov/rr/mopic/avprot/audioMD_v8.xsd), an extension schema developed by Library of Congress, or the AES audioObject XML schema which at the time of writing is under review as a standard.
3.7.4 If digitising from legacy collections, these schemas are useful not only for describing the digital file, but also the physical original. Care needs to be taken to avoid ambiguity about which object is being described in the metadata: it will be necessary to describe the work, its original manifestation and subsequent digital versions but it is critical to be able to distinguish what is being described in each instance. PREMIS distinguishes the various components in the sequence of change by associating them with events, and linking the resultant metadata through time.
3.8 Structural Metadata – METS
3.8.1 Time-based media are very often multimedia and complex. A field recording may consist of a sequence of events (songs, dances, rituals) accompanied by images and field notes. A lengthy oral history interview occupying more than one .wav file may also be accompanied by photographs of the speakers and written transcripts or linguistic analysis. Structural metadata provides an inventory of all relevant files and intelligence about external and internal relationships including preferred sequencing, e.g. the acts and scenes of an operatic recording. METS (Metadata Encoding and Transmission Standard, current version is 1.7) with its structural map (structMap) and file group (fileGrp) sections has a recent but proven track record of successful applications in audiovisual contexts (see fig. 3).
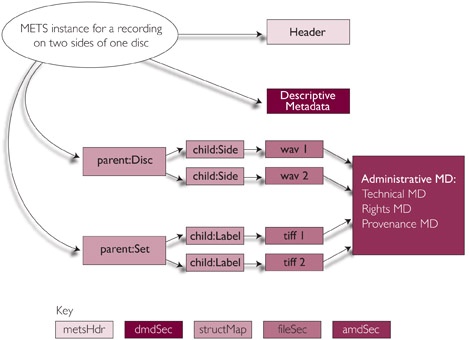
Fig 3: components of a METS instance and one possible set of relationships among them
3.8.2 The components of a METS instance are:
3.8.2.1 A header describes the METS object itself, such as who created this object, when, for what purpose. The header information supports management of the METS file proper.
3.8.2.2 The descriptive metadata section contains information describing the information resource represented by the digital object and enables it to be discovered.
3.8.2.3 The structural map, represented by the individual leaves and details, orders the digital files of the object into a browsable hierarchy.
3.8.2.4 The content file section, represented by images one through five, declares which digital files constitute the object. Files may be either embedded in the object or referenced.
3.8.2.5 The administrative metadata section contains information about the digital files declared in the content file section. This section subdivides into:
3.8.2.5.1 technical metadata, specifying the technical characteristics of a file
3.8.2.5.2 source metadata, specifying the source of capture (e.g.,direct capture or reformatted 4 x 5 transparency)
3.8.2.5.3 digital provenance metadata, specifying the changes a file has undergone since its birth
3.8.2.5.4 rights metadata, specifying the conditions of legal access.
3.8.2.6 The sections on technical metadata, source metadiata, and digital provenance metadata carry the information pertinent to digital preservation.
3.8.2.7 For the sake of completeness, the behaviour section, not shown above in Fig. 2, associates executables with a METS object. For example, a METS object may rely on a certain piece of code to instantiate for viewing, and the behavior section could reference that code.
3.8.3 Structural metadata may need to represent additional business objects:
3.8.3.1 user information (authentication)
3.8.3.2 rights and licenses (how an object may be used)
3.8.3.3 policies (how an object was selected by the archive)
3.8.3.4 services (copying and rights clearance)
3.8.3.5 organizations (collaborations, stakeholders, sources of funding).
3.8.4 These may be represented by files referenced to a specific address or URL. Explanatory annotations may be provided in the metadata for human readers.
3.9 Descriptive Metadata – Application Profiles, Dublin Core (DC)
3.9.1 Much of the effort devoted to metadata in the heritage sector has focussed on descriptive metadata as an offshoot of traditional cataloguing. However, it is clear that too much attention in this area (e.g. localised refinements of descriptive tags and controlled vocabularies) at the expense of other considerations described above will result in system shortcomings overall. Figure 4 demonstrates the various inter-dependencies that need to be in place, descriptive metadata tags being just one sub-set of all the elements in play.
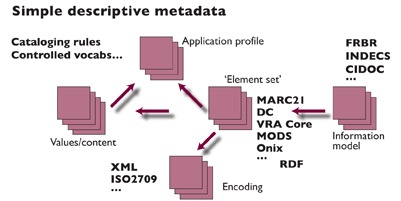
Fig 4: simple descriptive metadata (courtesy Dempsey, CLIR/DLF primer, 2005)
3.9.2 Interoperability must be a key component of any metadata strategy: elaborate systems devised independently for one archival repository by a dedicated team will be a recipe for low productivity, high costs and minimal impact. The result will be a metadata cottage industry incapable of expansion. Descriptive metadata is indeed a classic case of Richard Gabriel’s maxim ‘Worse is better’. Comparing two programme languages, one elegant but complex, the other awkward but simple, Gabriel predicted, correctly, that the language that was simpler would spread faster, and as a result, more people would come to care about improving the simple language than improving the complex one. This is demonstrated by the widespread adoption and success of Dublin Core (DC), initially regarded as an unlikely solution by the professionals on account of its rigorous simplicity.
3.9.3 The mission of DCMI (DC Metadata Initiative) has been to make it easier to find resources using the Internet through developing metadata standards for discovery across domains, defining frameworks for the interoperation of metadata sets and facilitating the development of community- or discipline-specific metadata sets that are consistent with these aims. It is a vocabulary of just fifteen elements for use in resource description and provides economically for all three categories of metadata. None of the elements is mandatory: all are repeatable, although implementers may specify otherwise in application profiles – see section 3.9.8 below. The name “Dublin” is due to its origin at a 1995 invitational workshop in Dublin, Ohio;”core” because its elements are broad and generic, usable for describing a wide range of resources. DC has been in widespread use for more than a decade and the fifteen element descriptions have been formally endorsed in the following standards: ISO Standard 15836-2003 of February 2003 [ISO15836 http://dublincore.org/documents/dces/#ISO15836 ] NISO Standard Z39.85-2007 of May 2007 [NISOZ3985 http://dublincore.org/documents/dces/#NISOZ3985 ] and IETF RFC 5013 of August 2007 [RFC5013 http://dublincore.org/documents/dces/#RFC5013 ].
Table 1 (below) lists the fifteen DC elements with their (shortened) official definitions and suggested interpretations for audiovisual contexts.
| DC element | DC definition | Audiovisual interpretation |
|---|---|---|
| Title | A name given to the resource | The main title associated with the recording |
| Subject | The topic of the resource | Main topics covered |
| Description | An account of the resource | Explanatory notes, interview summaries, descriptions of environmental or cultural context, list of contents |
| Creator | An entity primarily responsible for making the resource | Not authors or composers of the recorded works but the name of the archive |
| Publisher | An entity responsible for making the resource available | Not the publisher of the original document that has been digitized. Typically the publisher will be the same as the Creator |
| Contributor | An entity responsible for making contributions to the resource | Any named person or sound source.Will need suitable qualifier, such as role (e.g. performer, recordist) |
| Date | A point or period of time associated with an event in the lifecycle of the resource | Not the recording or (P) date of the original but a date relating to the resource itself |
| Type | The nature or genre of the resource | The domain of the resource, not the genre of the music. So Sound, not Jazz |
| Format | The file format, physical medium, or dimensions of the resource | The file format, not the original physical carrier |
| Identifier | An unambiguous reference to the resource within a given context | Likely to be the URI of the audio file |
| Source | A related resource from which the described resource is derived | A reference to a resource from which the present resource is derived |
| Language | A language of the resource | A language of the resource |
| Relation | A related resource | Reference to related objects |
| Coverage | The spatial or temporal topic of the resource, the spatial applicability of the resource, or the jurisdiction under which the resource is relevant | What the recording exemplifies, e.g. a cultural feature such as traditional songs or a dialect |
| Rights | Information about rights held in and over the resource | Information about rights held in and over the resoure |
Table 1: The DC 15 elements
3.9.4 The elements of DC have been expanded to include further properties. These are referred to as DC Terms. A number of these additional elements (‘terms’) will be useful for describing time-based media:
| DC Term | DC definition | Audiovisual interpretation |
|---|---|---|
| Alternative | Any form of the title used as a substitute or alternative to the formal title of the resource | An alternative title, e.g. a translated title, a pseudonym, an alternative ordering of elements in a generic title |
| Extent | The size or duration of the resource | File size and duration |
| extentOriginal | The physical or digital manifestation of the resource | The size or duration of the original source recording(s) |
| Spatial | Spatial characteristics of the intellectual content of the resource | Recording location, including topographical co-ordinates to support map interfaces |
| Temporal | Temporal characteristics of the intellectual content of the resource | Occasion on which recording was made |
| Created | Date of creation of the resource | Recording date and any other significant date in the lifecycle of the recording |
Table 2: DC Terms (a selection)
3.9.5 Implementers of DC may choose to use the fifteen elements either in their legacy dc: variant (e.g., http://purl.org/dc/elements/1.1/creator) or in the dcterms: variant (e.g., http://purl.org/dc/terms/creator) depending on application requirements. Over time, however, and especially if RDF is part of the metadata strategy, implementers are expected (and encouraged by DCMI) to use the semantically more precise dcterms: properties, as they more fully comply with best practice for machine-processable metadata.
3.9.6 Even in this expanded form, DC may lack the fine granularity required in a specialised audiovisual archive. The Contributor element, for example, will typically need to mention the role of the Contributor in the recording to avoid, for instance, confusing performers with composers or actors with dramatists. A list of common roles (or ‘relators’) for human agents has been devised (MARC relators) by the Library of Congress. Here are two examples of how they can be implemented.
<dcterms:contributor>
<marcrel:CMP>Beethoven, Ludwig van, 1770-1827</marcrel:CMP>
<marcrel:PRF>Quatuor Pascal</marcrel:PRF>
</dcterms:contributor>
<dcterms:contributor>
<marcrel:SPK>Greer, Germaine, 1939- (female)</marcrel:SPK>
<marcrel:SPK>McCulloch, Joseph, 1908-1990 (male)</marcrel:SPK>
</dcterms:contributor>
The first example tags ‘Beethoven’ as the composer (CMP) and ‘Quatuor Pascal’ as the performer (PRF). The second tags both contributors, Greer and McCulloch, as speakers (SPK) though does not go as far as determining who is the interviewer and who is the interviewee. That information would need to be conveyed elsewhere in the metadata, e.g. in Description or Title.
3.9.7 In this respect, other schema may be preferable, or could be included as additional extension schema (as illustrated in Fig. 2). MODS (Metadata Object Description Schema http://www.loc.gov/standards/mods/), for instance allows for more granularity in names and linkage with authority files, a reflection of its derivation from the MARC standard:
name
Subelements:
namePart
Attribute: type (date, family, given, termsOfAddress)
displayForm
affiliation
role
roleTerm
Attributes: type (code, text); authority
(see: http://www.loc.gov/standards/sourcelist/)
description
Attributes: ID; xlink; lang; xml:lang; script; transliteration
type (enumerated: personal, corporate, conference)
authority (see: http://www.loc.gov/standards/sourcelist/)
3.9.8 Using METS it would be admissible to include more than one set of descriptive metadata suited to different purposes, for example a Dublin Core set (for OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) compliance) and a more sophisticated MODS set for compliance with other initiatives, particularly exchange of records with MARC encoded systems. This ability to incorporate other standard approaches is one of the advantages of METS.
3.9.9 DC, under the governance of the Dublin Core Metadata Initiative (DCMI), continues to develop. On the one hand its value for networking resources is strengthened through closer association with semantic web tools such as RDF (see Nilsson et al, DCMI 2008) while on the other it aims to increase its relevance to the heritage sector through a formal association with RDA (Resource Description &Access http://www.collectionscanada.gc.ca/jsc/rda.html) due to be released in 2009. As RDA is seen as a timely successor to the Anglo America Cataloguing Rules this particular development may have major strategic implications for audiovisual archives that are part of national and university libraries. For broadcasting archives other developments based on DCMI are noteworthy At the time of writing the EBU (European Broadcast Union) is completing the development of the EBU Core Metadata Set, which is based on and compatible with Dublin Core.
3.9.10 The archive may wish to modify (expand, adapt) the core element set. Such modified sets, drawing on one or more existing namespace schemas (e.g. MODS and/or IEEE LOM as well as DC) are known as application profiles. All elements in an application profile are drawn from elsewhere, from distinct namespace schemas. If implementers wish to create ‘new’ elements that are not schematized elsewhere, for instance contributor roles unavailable in the MARC relators set (e.g. non-human agents such as species, machines, environments), then they must create their own namespace schema, and take responsibility for ‘declaring’ and maintaining that schema.
3.9.11 Application profiles include a list of the governing namespaces together with their current URL (preferably PURL – permanent URL). These are replicated in each metadata instance. There then follows a list of each data element together with permitted values and style of content. This may refer to in-house or additional rules and controlled vocabularies, e.g. thesauri of instrument names and genres, authority files of personal names and subjects. The profile will also specify mandatory schemes for particular elements such as dates (YYYY-MM-DD) and geographical co-ordinates and such standardised representations of location and time will be able to support map and timeline displays as non-textual retrieval devices.
| Name of Term | Title |
|---|---|
| Term URI | http://purl.org/dc/elements/1.1/title |
| Label | Title |
| Defined By | http://dublincore.org/documents/dcmi-terms/ |
| Source Definition | A name given to a resource |
| BLAP-S Definition | The title of the work or work component |
| Source Comments | Typically, a Title will be a name by which the source is formally known |
| BLAP-S Comments | If no title is available construct one that is derived from the resource or supply [no title]. Follow normal cataloguing practice for recording title in other languages using the ‘Alternative’ refinement.Where data are derived from the Sound Archive catalogue, this will equate to one of the following title fields in the following hierarchical order:Work title (1), Item title (2), Collection title (3), Product title (4), Original species (5) Broadcast title (6), Short title (7), Published series (8), Unpublished series (9) |
| Type of term | Element |
| Refines | |
| Refined by | Alternative |
| Has encoding scheme | |
| Obligation | Mandatory |
| Occurrence | Not repeatable |
Fig 5: Part of the British Library’s application profile of DC for sound (BLAP-S):
Namespaces used in this Application Profile
DCMI Metadata Terms http://dublincore.org/documents/dcmi-terms/
RDF http://www.w3.org/RDF/
MODS elements http://www.loc.gov/standards/mods/
TEL terms http://www.theeuropeanlibrary.org/metadatahandbook/telterms.html
BL Terms http://labs.bl.uk/metadata/blap/terms.html
MARCREL http://id.loc.gov/vocabulary/relators.html
3.9.12 The application profile therefore incorporates or draws on a data dictionary (a file defining the basic organisation of a database down to its individual fields and field types) or several data dictionaries, that may be maintained by an individual archive or shared with a community of archives. The PREMIS data dictionary (http://www.loc.gov/standards/premis/v2/premis-2-0.pdf currently version 2) relating exclusively to preservation is expected to be drawn on substantially. Its numerous elements are known as ‘Semantic units’. Preservation metadata provides intelligence about provenance, preservation activity, technical features, and aids in verifying the authenticity of a digital object. The PREMIS Working Group released its Data Dictionary for Preservation metadata in June 2005 and recommends its use in all preservation repositories regardless of the type of materials archived and the preservation strategies employed.
3.9.13 By defining application profiles and, most importantly by declaring them, implementers can share information about their schemas in order to collaborate widely on universal tasks such as long-term preservation
3.10 Sources of Metadata
3.10.1 Archives should not expect to create all descriptive metadata by themselves from scratch (the old way). Indeed, given the in-built lifecycle relationship between resources and metadata such a notion will be unworkable. There are several sources of metadata, especially the descriptive category that should be exploited to reduce costs and provide enrichment through extending the means of input. There are three main sources: professional, contributed and intentional (Dempsey:2007): they may be deployed alongside each other.
3.10.2 Professional sources means drawing on the locked-in value of legacy databases, authority files and controlled vocabularies which are valuable for published or replicated materials. It includes industry databases, as well as archive catalogues. Such sources, especially archive catalogues, are notoriously incomplete and incapable of interoperation without sophisticated conversion programmes and complex protocols. There are almost as many data standards in operation in the recording and broadcasting industries and the audiovisual heritage sector as there are separate databases. The lack of a universal resolver for AV, such as ISBN for print, is a continuing hindrance and after decades of discographical endeavour there is still disagreement about what constitutes a catalogue record: is it an individual track or is it a sequence of tracks that make up an intellectual unit such as a multi-sectioned musical or literary work? Is it the sum total of tracks on a single carrier or set of carriers, in other words, is the physical carrier the catalogue unit? Evidently, an agency that has chosen one of the more granular definitions will find it much easier to export its legacy data successfully into a metadata infrastructure. Belt and braces approaches to data export based on Z39.50 (http://www.loc.gov/z3950/agency/ protocol for information retrieval) and SRW/SRU (a protocol for search and retrieve via standardized URL’s with a standardized XML response) will continue to provide a degree of success, as will the ability of computers to harvest metadata from a central resource. However, more effective investment should be made in the shared production of resources which identify and describe names, subjects, places, time periods, and works.
3.10.3 Contributed sources means user generated content. A major phenomenon of recent years has been the emergence of many sites which invite, aggregate and mine data contributed by users, and mobilize that data to rank, recommend and relate resources. These include, for example, YouTube and LastFM. These sites have value in that they reveal relations between people and between people and resources as well as information about the resources themselves. Libraries have begun to experiment with these approaches and there are real advantages to be gained by allowing users to augment professionally sourced metadata. So-called Web 2.0 features that support user contribution and syndication are becoming commonplace features of available content management systems.
3.10.4 Intentional means data collected about use and usage that can enhance resource discovery. The concept is borrowed from the commercial sector, Amazon recommendations, for instance, that are based on aggregate purchase choices. Similar algorithms could be used to rank objects in a resource. This type of data has emerged as a central factor in successful websites, providing useful paths through intimidating amounts of complex information.
3.11 Future Development Needs
3.11.1 For all the recent work and developments, metadata remains an immature science, though this chapter will have demonstrated that a number of substantial building blocks (data dictionaries, schemas, ontologies, and encodings) are now in place to begin to match the appetite of researchers for more easily accessible AV content and the long-held ambition of our profession to safeguard its persistence. To achieve faster progress it will be necessary to find common ground between public and commercial sectors and between the different categories of audiovisual archives, each of which has been busy devising its own tools and standards.
3.11.2 Some success has been achieved with automatic derivation of metadata from resources.We need to do more, especially as existing manual processes do not scale very well. Moreover, metadata production does not look sustainable unless more cost is taken out of the process.”We should not be adding cost and complexity, which is what tends to happen when development is through multiple consensus-making channels which respond to the imperatives of a part only of the service environment” (Dempsey:2005).
3.11.3 The problem of the reconciliation of databases, i.e. the capacity of the system to understand that items are semantically identical although they may be represented in different ways, remains an open issue. There is significant research being undertaken to resolve this issue,but a widely suitable general solution has yet to emerge. This issue is also very important for the management of the persistence in the OAIS as the following example demonstrates. The semantic expression that Wolfgang Amadeus Mozart is the composer of most of the parts of the Requiem (K.626) is represented in a totally different way in FRBR modelling when compared to a list of simple DCMI statements. In CDMI ‘Composer’ is a refinement of ‘contributor’ and ‘Mozart’ is its property; while in FRBR modelling, ‘composer’ is a relation between a physical person and an opus. The use of controlled vocabularies is also a way of ensuring that W.A. Mozart represents the same person as Mozart.