3: Métadonnées
3.1 Introduction
3.1.1 Les métadonnées sont des données structurées qui améliorent les opérations sur les ressources, telles la conservation, le reformatage, l'analyse, la découverte et l'exploitation. Elles sont les plus efficaces dans un environnement de réseau internet, mais elles demeurent nécessaires pour tout stockage et conservation de documents numériques. Les métadonnées informent l'utilisateur final (personnes et programmes informatisés) sur la manière dont les données doivent être interprétées. Les métadonnées revêtent une importance capitale en matière de compréhension, de cohérence et de bon fonctionnement pour chacune des confrontations avec l'objet archivé quel que soit l'instant de son cycle de vie et avec tout objet associé ou dérivé de celui-ci.
3.1.2 Il peut être utile de désigner les métadonnées par les termes fonctionnels de "informations structurées renseignant une ressource » : « structurées » parce que lisibles par une machine, [aussi bien que par des personnes] ; « renseignant » parce qu’elles supposent une recherche d’un agent sur la ressource en question ; « ressource » car tout objet identifiable peut avoir des métadonnées qui lui soient associées" (Dempsey 2005). De telles informations structurées (ou codées) renseignant des ressources (mentionnées également par métadonnées d'instance) peuvent être très simples, comporter un identifiant uniforme de ressource (Uniform Resource Identifier (URI) avec une simple paire de parenthèses angulaires <> pour containeur ou programme wrapper, et un namespace. Habituellement, les représentations peuvent se développer de manière très élaborée et devenir modulaires, comporter de nombreux containeurs emboîtés, plusieurs couches de wrappers, chacun d'entre eux s'appuyant sur un modèle de namespace et assemblés à différentes phases du workflow (flux d'information) pendant une période prolongée. Une personne ne pourrait qu'exceptionnellement créer en une session les métadonnées d'instance définitives et complètes d'un objet numérique permanent.
3.1.3 Quelle que soit la manière dont les nombreuses versions de fichiers audio peuvent être créées au fil du temps, toutes les propriétés significatives des fichiers d'archivage doivent rester inchangées. Le même principe s'applique pour toute métadonnée embarquée (voir paragraphe 3.1.4 ci dessous). Toutefois, les données de n'importe quel objet peuvent être modifiées dans le temps : nouvelles informations disponibles, changement d'avis, modification de la terminologie, décès de contributeurs, expiration ou renégociation des droits. Par conséquent, il est souvent conseillé de bien séparer tout ou partie des fichiers audio des fichiers de métadonnées, d'établir des liaisons entre ceux-ci, d'effectuer des mises à jour des métadonnées chaque fois que des informations et des ressources sont disponibles. Bien que lourde, l'opération d'éditing des métadonnées d'un fichier est possible. Pour les plus grandes collections, elle ne devrait pas s'intensifier si les démarches sont bien adaptées. En conséquence, l'extension dans laquelle les données sont intégrées aussi bien dans les fichiers que dans des systèmes de gestion de données séparées, sera déterminée par la taille de la collection, par le degré de complexité du système considéré et par les capacités du personnel du service d'archives.
3.1.4 Les métadonnées peuvent être intégrées aux fichiers audio, ce qui constitue une solution acceptable telle que suggérée pour une approche à petite échelle de systèmes de stockage numérique (voir paragraphe 7.4 Métadonnées élémentaires). Le format Broadcast Wave Format (BWF) normalisé par l'Union Européenne de Radiodiffusion (UER /EBU) constitue un exemple d'intégration de métadonnées audio qui permet le stockage d'un nombre limité de données descriptives dans le fichier .wav (voir paragraphe 2.8 Formats de fichiers). Un des avantages du stockage de métadonnées dans le fichier sera d'écarter les risques de perte des liens entre les métadonnées et les contenus audio numériques. Le format BWF supporte l'acquisition des processus de traitements des métadonnées ainsi que de nombreux outils associés. Il peut en outre accueillir les données et nourrir la partie du format global BEXT (extension radiodiffusion). Par conséquent, les métadonnées peuvent inclure l'historique de codage, qui est grossièrement défini dans la norme BWF, ce qui permet de renseigner le processus ayant conduit à la création de l'objet audio numérique. Ceci présente des similitudes avec les événements relevés dans les recommandations PREMIS (voir 3.5.2, 3.7.3 et Fig. 1). Lors des opérations de numérisation de sources analogiques, le format global BEXT peut aussi être utilisé pour stocker des informations qualifiant le contenu audio pendant la création d'un objet numérique à partir d'une source numérique, de CD ou DAT par exemple, le format global BEXT peut être utilisé pour enregistrer les erreurs susceptibles de se produire lors du processus d'encodage.
A=<ANALOGUE> Information sur le parcours du signal audio analogique A=<PCM> Information sur le parcours du signal audio numérique F=<48000, 44100, etc.> Fréquence d'échantillonnage [Hz] W=<16,18,20,22,24, etc.> Longueur de mot [bits] M=<mono, stereo, 2-channel> Mode d'enregistrement T=<free ASCII-text-string> Texte commentaires Historique de codage : BWF (http://www.ebu.ch/CMSimages/en/tec_text_r98-1999_tcm6-4709.pdf) A=ANALOGUE, M=Stereo, T=Studer A820;SN1345;19.05;Reel;AMPEX 406 A=PCM, F=48000, W=24, M=stereo, T=Apogee PSX-100;SN1516;RME DIG196/8 Pro A=PCM, F=48000, W=24, M=stereo, T=WAV A=PCM, F=48000, W=24, M=stereo, T=2006-02-20 File Parser brand name A=PCM, F=48000, W=24, M=stereo, T=File Converter brand name 2006-02-20;08:10:02
Fig. 1 National Library of Australia : interprétation de l'historique de codage de la conversion d'un original sur bande en bobine libre au format BWF utilisant une base de données et des systèmes automatiques.
3.1.5 La Bibliothèque du Congrès (Library of Congress) a réalisé des travaux sur la formalisation et le développement des différents types de données brutes des fichiers BWF. Embedded Metadata and Identifiers for Digital Audio Files and Objects (Métadonnées et identifiants de fichiers et objets audio numériques intégrés) : les recommandations pour les fichiers WAVE et BWF actuels (Recommendations for WAVE and BWF Files Today) constituent la dernière ébauche proposée aux commentaires, http://home.comcast.net/~cfle/AVdocs/Embed_Audio_08103.doc. Le projet AES X098C constitue un autre développement de la documentation des modalités et de la provenance des métadonnées.
3.1.6 Il existe toutefois de nombreux avantages à maintenir la séparation des métadonnées et des contenus en utilisant par exemple une structure standard telle que METS (Metadata Encoding and Transmission Standard voir paragraphe 3-8 Métadonnées structurelles - METS). Il est plus simple de mettre à jour, de maintenir et de corriger des métadonnées dans le cas d'un entrepôt séparé. L'extension des champs de métadonnées réalisée pour incorporer de nouveaux critères, de nouvelles informations, est possible uniquement dans le cas d'un système présentant cette souplesse. Afin de pouvoir partager des informations de différentes manières, un entrepôt séparé est nécessaire ; des métadonnées pourront ainsi être créées et utilisées par un tel système. Pour des collections de plus grande taille, la charge consistant à maintenir les métadonnées uniquement dans les en-têtes des fichiers BWF serait insoutenable. MPEG-7 nécessite la séparation des contenus audio et des métadonnées descriptives, même si les descriptions peuvent être multiplexées avec les contenus en tant que segments alternatifs de données.
3.1.7 Il est possible évidemment d'envelopper un fichier BWF avec des métadonnées encore mieux renseignées, la disponibilité des informations conservées dans BWF est établie mais limitée, cette approche présente l'avantage des deux approches. Un autre exemple d'intégration est donné par les marqueurs (tags) de métadonnées qui doivent être présents dans les fichiers de contrôle d'accès afin que l'utilisateur soit en mesure de vérifier que l'objet téléchargé ou sur le point d'être consulté en mode streaming est bien l'objet repéré et sélectionné. ID3, le marqueur utilisé pour les fichiers MP3 décrivant le contenu de l'information, est lisible et interprété par la plupart des lecteurs, il permet de disposer d'un jeu minimum de métadonnées descriptives. L'encodage METS a été examiné en tant que possible containeur à la fois des métadonnées d'empaquetage et des contenus, même si la taille potentielle de tels documents laisse à penser qu'une telle option n'est guère viable.
3.1.8 Pour séparer les métadonnées des contenus (avec redondance possible si ces derniers contiennent un certain nombre de métadonnées), une solution générale se dessine à partir des travaux entrepris par plusieurs universités en relation avec les principales firmes industrielles tels que SUN Microsystems, Hewlett-Packard et IBM. Le concept consiste toujours à stocker la représentation d'une ressource au moyen de deux fichiers regroupés : un fichier comportant les "contenus", l'autre les métadonnées associées à ce contenu. Ce deuxième fichier comprend :
3.1.8.1 La liste des identifiants pour chaque motif logique. Il s'agit en fait d’une série d'"alias" relatifs à l'URN et de la représentation localisée de la ressource (URL).
3.1.8.2 Les métadonnées techniques (bits par échantillon / taux d'échantillonnage ; définition précise du format ; l'ontologie associée éventuellement).
3.1.8.3 Les métadonnées factuelles (Coordonnées GPS / Temps codé universel / Numéro de série des équipements / Opérateur / ...).
3.1.8.4 Les métadonnées sémantiques.
3.1.9 En résumé, la plupart des systèmes adoptent une approche pratique conçue avec des métadonnées à la fois incorporées aux fichiers et maintenues à part, établissant des priorités (i.e. ce qui constitue la source primaire d'information) et des protocoles (règles de maintenance des données) afin de préserver l'intégrité des ressources.
3.2 Production
3.2.1 La suite de ce chapitre suppose que dans la plupart des cas, les fichiers audio et les fichiers de métadonnées sont créés et gérés séparément. Dans ce cas, la production des métadonnées implique une logistique - modification des informations, documents et services en ligne à bas coût. Toutefois, les collections de taille réduite ou les services d'archives en première phase de leur développement, peuvent trouver avantage dans l'incorporation des métadonnées dans les fichiers BWF et dans la possibilité d'alimenter sélectivement un sous-ensemble d'informations comme décrit ci-dessous. Si cela est fait convenablement, avec une bonne compréhension des standards et des schémas discutés dans ce chapitre, une telle approche est viable et pourra migrer sur un système entièrement implémenté comme décrit ci-dessous. Même dans le cas d'une décision prise par un service d'archives d'intégrer tout ou partie des métadonnées dans l'en-tête du fichier, ou bien d'assurer séparément la gestion de certaines métadonnées seulement, ce chapitre fournit les informations sur une telle approche. (Voir également le Chapitre 7 Approches à petite échelle des systèmes de stockage numérique).
3.2.2 Jusqu'à une époque récente, les producteurs d'informations concernant les enregistrements travaillaient dans une équipe de catalogage ou une équipe technique et leur production convergeait rarement. Les espaces en réseaux brouillent les délimitations historiques. Il va sans dire que l’intégration de la logistique dans un workflow réussi exige en outre l'engagement de professionnels qui comprennent les modes de fonctionnement et de connectivité des espaces en réseaux. La production de métadonnées implique donc une collaboration étroite entre techniciens audio, informaticiens et spécialistes des sujets concernés. Elle exige également une gestion attentive pour mettre en œuvre une stratégie claire assurant la durabilité et l'adaptation des flux des tâches à accomplir (workflow) dans le contexte du développement rapide des technologies et des applications associées à ces processus.
3.2.3 Les métadonnées sont comme les intérêts - elles capitalisent au cours du temps. Si les métadonnées ont été crées de manière minutieuse et cohérente, on peut envisager l'utilisation de cet atout pour un nombre pratiquement infini de nouvelles façons de répondre aux besoins de nombreux types d'utilisateurs, par des multi-versions, par des processus d'exploitation des données (data mining). Mais les ressources et les problèmes de conception intellectuelle et technique impliqués dans le développement et la gestion des métadonnées ne sont pas négligeables. Par exemple, certaines questions clef que tout gestionnaire de système de métadonnées doit aborder incluent :
3.2.3.1 L'identification de la structure de métadonnées ou de structures d'extensions à réaliser pour répondre aux besoins des équipes de production, du dépôt lui-même, des utilisateurs ;
3.2.3.2 Le choix des caractéristiques essentielles des métadonnées qui doivent lui permettre d’atteindre son objectif, et la granularité dont chaque type de métadonnée a besoin. Les métadonnées étant produites pour le long terme, elles feront probablement l'objet d'un compromis systématique entre les coûts de développement et de gestion des métadonnées propres à couvrir le besoin du moment, et la création de métadonnées qui répondent à des demandes futures et peut-être non anticipées.
3.2.3.3 L'assurance que les schémas de métadonnées mis en application sont les plus courants ;
3.2.3.4 L'interopérabilité est un autre facteur ; à l'ère numérique, aucun service d'archives n'est une île. Pour envoyer correctement un contenu à un autre service ou à un autre organisme, il est nécessaire de définir une structure et une syntaxe communes. C'est en arrière plan le principe des formats METS et BWF.
3.2.4 Il convient de prévoir le niveau de complexité dans des environnements réseaux où les responsabilités de gestion des fichiers de données sont partagées. Mais une telle complexité est tout simplement ingérable ; cependant, si l'on s'accroche aux anciennes méthodes de travail remontant aux premiers jours de présence des ordinateurs dans les bibliothèques et les archives, avant que le Web et l'XML n'existent, ainsi que l'exprimait Richard Feynman pour sa discipline, la physique, "vous ne pouvez vous attendre à ce que d'anciens concepts fonctionnent dans un nouveau contexte". Il est nécessaire de définir de nouvelles exigences pour le système et d'estimer quels changements culturels accomplir. Cela permettra alors de disposer d'infrastructures de métadonnées d'archives audiovisuelles viables et évolutives.
3.3 Infrastructure
3.3.1 Nous n'avons pas besoin de norme "discographique" de métadonnées : une résolution pour un domaine spécifique ne constituerait qu'une contrainte impraticable. Il nous faut disposer d'une infrastructure de métadonnées dont plusieurs composantes essentielles restent communes avec d'autres domaines, chacune pouvant être différente localement (sous forme d'un schéma d'extension), et qui puisse être mise en application par n'importe quel service d'archives audiovisuelles. Présentons quelques une des qualités essentielles pouvant aider à définir les exigences structurelles et fonctionnelles :
3.3.1.1 Versatilité : En ce qui concerne les métadonnées elles-mêmes, le système doit être capable de mettre en œuvre les entrées, la fusion, l'indexation, les perfectionnements et l'accès des utilisateurs à celles-ci à partir de différentes sources décrivant différents objets. Le système doit aussi être capable de définir les structures logiques et physiques ; les structures logiques représentant des entités intellectuelles tandis que les structures physiques représentent les médias physiques (ou supports) qui constituent la source des objets numériques. Le système ne doit pas être lié à un schéma particulier de métadonnées : il doit être possible de mixer des schémas, en application des profils (voir 3.9.8) adaptés auxbesoins particuliers des services d'archives sans pour autant compromettre l'interopérabilité. Le défi consiste à élaborer un système pouvant accueillir une telle diversité sans complication inutile pour l'utilisateur peu exigeant, et qui n'empêche pas ceux qui exigent au contraire une plus grande marge de manœuvre de mener des activités plus complexes.
3.3.1.2 Extensibilité : donner la possibilité d'accueillir une large gamme de sujets, de différents types de documents (i.e. images et fichiers texte) et des entités d'activités (authentification Utilisateur, licences d'utilisation, politique d'acquisition, etc.). Faire en sorte que les extensions puissent être développées et appliquées ou bien totalement ignorées sans casser l'ensemble ; en d'autres termes, accepter les expérimentations : les solutions consistant à implémenter des métadonnées relèvent d'une science immature.
3.3.1.3 Durabilité : Migration possible, maintenance peu onéreuse, facilité d'utilisation, pertinence à long terme et adaptation selon les objectifs fixés.
3.3.1.4 Modularité : Les systèmes utilisés pour créer ou insérer les métadonnées, les fusionner, les indexer et les exporter devront être de nature modulaire afin qu'il soit possible de remplacer un élément spécifique par un autre sans détruire pour autant l'ensemble.
3.3.1.5 Granularité : La granularité des métadonnées devra être suffisante pour subvenir à toutes les utilisations souhaitées. La granularité des métadonnées peut facilement être insuffisante tandis que dans certains cas, rares, la granularité est trop élevée pour certains usages.
3.3.1.6 Liquidité : Ecriture unique, nombreuses utilisations. La liquidité permet l'auto-documentation des objets numériques et de leur représentation au fil du temps ; les métadonnées d'archivage seront plus sollicitées dans de nombreux espaces de réseaux, elles procureront des retours sur investissements d'origine conséquents, en termes de financements et de temps.
3.3.1.7 Ouverture et transparence : Interopérabilité des supports avec d'autres systèmes. Pour répondre aux exigences telles que l'extensibilité, les normes, les protocoles, et les logiciels intégrés devront être aussi ouverts et transparents que possible.
3.3.1.8 Relationnel (hiérarchie / séquence / provenance) : Relations parents - enfants qui doivent être exprimées, enchaînement correct des séquences, ex. les scènes d'un spectacle dramatique, et dérivations. En ce qui concerne les items numériques : être capable de dresser précisément la cartographie et l'instanciation des supports originaux et du contenu intellectuel de leur fichier. Des procédures utiles pour s'assurer de l'authenticité de l'objet archivé (Tennant 2004).
3.3.2 Cette recette de la diversité est en soi une forme d'ouverture. Si une norme W3C (World Wide Web Consortium) telle que Extensible Markup Language (XML) (Langage de balisage extensible), langage largement adopté, est sélectionné, cela n'empêche pas des mises en œuvre particulières y compris la combinaison de normes telle que Material Exchange Format (MXF) (Formats d'échange des contenus) et Advance Authoring Format (AAF) (Formats d'édition avancée) de Microsoft.
3.3.3 Sur le plan pratique, bien que MXF soit un format ouvert, l'intégration des métadonnées dans celui-ci s'effectue généralement par un processus propriétaire. Le format MXF présente d'autres avantages pour l'industrie radiophonique, il peut servir à la diffusion professionnelle de programmes en continu (streaming) tandis que d'autres formats containeurs n'acceptent que les téléchargements de fichiers complets. L'utilisation de MXF en tant que conteneur de contenus et de métadonnées pour l'archivage ne devra être acceptée qu'après remplacement de toutes les métadonnées aux formats propriétaire par des formats libres.
3.3.4 On a écrit et dit tant de choses à propos de XML que ce langage pourrait facilement être pris pour une panacée. XML n'est pas une solution en soi, mais une manière d'aborder l'organisation et la réutilisation des contenus. Sa très grande puissance a résidé dans la combinaison de celui-ci avec une palette impressionnante d'outils et de technologies associées et qui continuent de se développer dans le but de réaliser des économies par la réutilisation et la modification de données. A ce titre, XML est devenu de-facto une norme pour représenter les métadonnées de description des ressources sur internet. La gestion avec XML s'est poursuivie dans l'euphorie pendant une décennie grâce au développement de nombreuses sources libres (open sources) et outils d'éditing XML (Voir 3.6.2).
3.3.5 Bien qu'il soit fait référence dans ce chapitre à des formats de métadonnées spécifiques utilisés actuellement ou annoncés, cela ne signifie pas pour autant qu'ils aient un caractère normatif. Considérant leurs qualités essentielles (paragraphe 3.3.1), la maintenance technique détaillée, explicite, exhaustive et discrète, la création de données et les changements de politique, avec dates et responsabilités, les futures migrations et les nouvelles versions ne nécessiteront pas de changements substantiels de l'infrastructure de base. Une structure robuste de métadonnées devra être capable d'accueillir de nouveaux formats de métadonnées par la création d'outils spécifiques, tels que des crosswalks (tables de conversion), ou des algorithmes de transcodage efficaces et précis d’un schéma encodé à un autre. Un certain nombre de crosswalks existent déjà pour des formats tels que MARC, MODS, MPEG-7 Path, SMPTE et Dublin Core. Outre l'utilisation des correspondances crosswalks qui permettent de transformer les métadonnées d'un format à un autre, elles peuvent également être utilisées pour fusionner deux formats de métadonnées ou plus en un troisième, ou bien encore en un jeu d'index consultables. Etant donné un format containeur / transfert bien choisi tel que METS, pratiquement tous les formats tels que MARC-XML, Dublin Core, MODS, SMPTE (etc.), pourront être adaptés. En outre, cette infrastructure ouverte permettra aux services d'archives d'absorber les enregistrements du catalogue, en partie ou en totalité, ceci dans le cadre de leur système légal tout en offrant de nouveaux services tels que la création de métadonnées utilisables pour la collecte - voir OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) (Protocole pour la collecte des métadonnées de l'initiative pour les Archives ouvertes.
3.4 Projet - Ontologies
3.4.1 Ayant satisfait aux plus hauts niveaux d'exigence, une conception viable de métadonnées prendra forme, dans les moindres détails, à partir d'un modèle d'informations ou ontologies1. Différentes ontologies peuvent être justifiées en fonction du nombre d'opérations à effectuer. On recommande le CIDOC's CRM (Conceptual Reference Model http://cidoc.ics.forth.gr/) (Modèle sémantique de référence) pour les institutions relevant du patrimoine culturel (musées, bibliothèques et archives) ; Le modèle FRBR (Functional Requirements for Bibliographic Record) (Fonctionnalités requises des notices bibliographiques) http://www.loc.gov/cds/FRBR.hml) s'appliquera pour les archives constituées principalement d'enregistrements de spectacles musicaux ou d'œuvres littéraires, son action est renforcée par l'association des règles de catalogage RDA (Resource Description and Access) (Description et accès des ressources) et du groupe de travail DCMI (Dublin Core Metadata Initiative) (Initiative de métadonnées du Dublin Core (IMDC)). L'architecture COA (Contextual Ontology Architecture (Architecture des ontologies contextuelles) http://www.rightcom.com/Portals/O/format_Ontology_for_Media_Rights_Trans...) est adaptée aux objectifs visés lorsque la gestion des droits est primordiale, ainsi en est-il de la norme de gestion des droits du groupe Motion Picture Expert Group, MPEG-21. Le cadre de description des ressources RDF (Resource Description Framework http://www.w3.org/RDF/), qui définit des spécifications versatiles et relativement simples deviendra une composante du modèle, notamment lors de la création des ressources Web à partir du dépôt d'archives : il pourra à son tour accueillir des applications bien connues telles que RSS (Really Simple Syndication) (Syndication vraiment simple) qui fournissent l'information (syndication). D'autres candidats permettant d'améliorer la manipulation du système et d'interpréter les métadonnées peuvent être découverts dans la "famille" des nouvelles ontologies utilisant le langage OWL (Web Ontology Language) (Langage d'ontologie Web). Les opérations de définition et de lecture des ontologies énoncées dans OWL peuvent être facilement réalisées en utilisant l'outil ouvert "Protégé" de l'Université de Stanford : http://protege.stanford.edu/. OWL peut être utilisé depuis une simple définition de termes jusqu'à une modélisation orientée objet complexe.
Ontologies: Définition W3C : L'ontologie définit la terminologie utilisée pour décrire et représenter un champ de la connaissance. Des personnes, des bases de données, des applications utilisent les ontologies lorsque des domaines d'information doivent être partagés. (On désigne par domaine un sujet spécifique ou bien un secteur de la connaissance tel que la médecine, la fabrication d'outils, les biens immobiliers, la réparation automobile, la gestion financière, etc.). Les ontologies concernent les définitions, utilisables dans un environnement informatique, des concepts fondamentaux et de leurs relations dans un domaine considéré (dans ce cas et de manière plus générale dans ce document, on notera que cette définition s'entend dans l'acception technique des informaticiens programmeurs). Les ontologies codent la connaissance d'un domaine mais aussi de domaines plus vastes. De cette manière, elles rendent la connaissance réutilisable.
3.5 Projet – Ensemble d'éléments
3.5.1 Un ensemble d'éléments de métadonnées prend ensuite sa place dans le concept global. Trois catégories principales ou groupements de métadonnées sont communément décrites ici :
3.5.1.1 Les métadonnées descriptives, utilisées pour découvrir et identifier un objet.
3.5.1.2 Les métadonnées de structure utilisées pour afficher et diriger un sujet particulier vers l'utilisateur et pour insérer des informations dans l'organisation interne de cet objet, par exemple une séquence d'événements proposés et leurs relations avec d'autres objets, tels que des images ou des transcriptions d'entretiens.
3.5.1.3 Les métadonnées d'administration, qui représentent l'information de gestion des objets (tels que les namespaces (espaces de nommage) qui acceptent la métadonnée elle même), les dates de création ou de modification de l'objet, les métadonnées techniques (format de fichier du contenu validé, durée, taux d'échantillonnage, etc.), information portant sur les droits et les licences. Cette catégorie comprend l'essentiel des données relatives à la conservation.
3.5.2 Quelles que soient les opérations à conduire, chacune de ces trois catégories : descriptive, structurelle et administrative, doit être présente, même si différents sous-ensembles de données peuvent se trouver dans n'importe quel fichier ou programme d'instanciation. Les métadonnées venant appuyer les objectifs de conservation - "informations qui renforcent et documentent les processus de conservation" (PREMIS) - le processus pourra s'enrichir de données à propos de la provenance des objets, leur authenticité, les actions effectuées sur ceux-ci. Les métadonnées de conservation participant au processus de recherche, certaines d'entre-elles ou la totalité se montreront utiles à l'utilisateur final (en garantissant l'authenticité par exemple) ; pourtant, il serait plus important d'élaborer et de renforcer les données descriptives, structurelles et relatives aux licences, de disposer de moyens de transformation des métadonnées brutes en mode de présentation intuitive ou bien de les préparer pour le moissonnage ou pour des interactions d'utilisateurs externes en réseau. Il va sans dire qu'un item introuvable ne pourra ni être conservé, ni être écouté, aussi, plus on intégrera des métadonnées concernant de telles opérations, mieux ce sera.
3.5.3 Chacun de ces trois regroupement de métadonnées pourra être compilé séparément : les métadonnées administratives (technique), par exemple les produits dérivés de la numérisation de masse ; les métadonnées descriptives issues de l'export d'une ancienne base de données ; les métadonnées concernant les droits tels que la liquidation, qui seront complétées, et les licences signées. Les résultats de ces différentes compilations devront être réunis en une simple instance de métadonnées ou bien en un ensemble de fichiers reliés avec indication du statut de conservation. Il sera essentiel de communiquer tous ces éléments de métadonnées au schéma ou au DTD (Document Type Definition) (Définition du type de document). Sinon les métadonnées resteront comme une "grosse goutte", une accumulation de données lisibles pour l'humain mais inintelligibles pour les machines.
3.6 Projet – Codage et schémas
3.6.1 De manière analogue aux signaux audio codés en fichier WAV, dont les spécifications sont décrites et publiées, il est nécessaire de coder le jeu d'éléments : en langage XML, peut-être en combinaison avec RDF, selon la recommandation énoncée ci-dessus. Cette spécification sera précisée dans la première ligne de chaque instance de métadonnée <?xml version="1.0"encoding="UTE-8"?>. Ainsi, acquiert-il par lui-même de l'intelligence : c'est un peu comme dire à des auditeurs que la page du livret du CD qu'ils sont en train de lire est en papier et qu'elle doit être préservée d'une certaine manière. Les étapes suivantes produisent de l'intelligence (souvenons-nous, pour les machines tout autant que pour les personnes) à propos des schémas prévisibles et de la sémantique des données rencontrés dans les fichiers restants. Le reste des en-têtes de fichiers des métadonnées consiste typiquement en une séquence d'espaces de noms (namespaces) attribuée à d'autres normes et schémas (habituellement désignés comme "schéma d'extension") lors de la conception du projet.
<mets:mets xmlns:mets="http://www.loc.gov/standards/mets/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:dc="http://dublincore.org/documents/dces/" xmlns:xlink="http://www.w3.org/TR/xlink" xmlns:dcterms="http://dublincore.org/documents/dcmi-terms/" xmlns:dcmitype="http://purl.org/dc/dcmitype" xmlns:tel="http://www.theeuropeanlibrary.org/metadatahandbook/telterms.html" xmlns:mods="http://www.loc.gov/mods" xmlns:cld="http://www.ukoln.ac.uk/metadata/rslp/schema/" xmlns:blap="http://labs.bl.uk/metada/blap/terms.html" xmlns:marcrel="http://www.loc.gov/loc.terms/relators/" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#type" xmlns:blapsi="http://sound.bl.uk/blapsi.xml"xmlsn:namespace-prefix="blapsi">
Fig. 2 : Ensemble des espaces de noms (namespaces) utilisés dans les profils METS de la British Library pour les enregistrements sonores
3.6.2 De telles spécifications intelligentes, en XML, sont appelées schémas XML qui succèdent aux DTDs. Les DTDs sont encore couramment utilisées considérant la relative facilité de leur compilation. Le schéma demeurera dans un fichier avec l'extension .xsd (XML Schema Definition), il possèdera son propre namespace auquel d'autres opérations et implémentations pourront se référer. Pour être compilés, les schémas nécessitent de l'expertise. Heureusement, les outils open source sont disponibles, qui permettent à un système informatique de déduire un schéma d'un fichier XML bien fait. Des outils sont également disponibles pour effectuer la conversion XML en d'autres formats, tel que .pdf ou bien des documents .rtf (Word) en XML. Le schéma peut aussi incorporer des moyens idéalisés pour afficher les données selon des fichiers XLST. Les schémas (et les namespaces) de métadonnées descriptives seront détaillés au paragraphe 3.9 Métadonnées de description - Profils d'application, Dublin Core (DC) ci-dessous.
3.6.3 Pour résumer les relations présentées ci-dessus, un schéma XML ou DTD décrit une structure XML qui balise le contenu textuel au format d'un fichier codé XML. Le fichier (ou instance) contiendra un ou plusieurs namespaces représentant le schéma étendu de meilleure qualité que la structure XML pourrait déployer.
3.7 Métadonnées d'administration – Métadonnées de conservation
3.7.1 Les informations décrites dans ce paragraphe font partie du regroupement des métadonnées administratives. Celles-ci rassemblent les informations de l'en-tête des fichiers audio et encodent les informations d'exploitation nécessaires. De cette manière, le système informatique reconnaît le fichier et la manière dont il doit être utilisé grâce à l'association du fichier d'extension avec un logiciel particulier, et grâce à la lecture de l'information codée dans l'en-tête du fichier. Ces informations doivent aussi être référencées dans un fichier à part afin de faciliter la gestion et les futurs accès, car les extensions de fichiers constituent, au mieux, des indicateurs ambigus des fonctionnalités du fichier. Les champs qui décrivent cette information explicite, y compris le type et la version, peuvent-être automatiquement extraits des en-têtes du fichier et utilisés pour alimenter les champs du système de gestion des métadonnées. Si un système d'exploitation en cours ou à venir n'a pas la capacité d'activer un fichier .wav ou de lire une instance .xml par exemple, le logiciel ne pourra reconnaître l'extension ni accéder au fichier ou déterminer son type. En explicitant cette information dans l'inscription d'une métadonnée, on permet au futur utilisateur de disposer des données de gestion et d'être en mesure de décoder les données d'information. Les normes , en cours d’élaboration dans l'AES-X098B et qui seront publiées par l'Audio Engineering Society sous le titre AES57 "AES standard for audio metadata - audio object structures for preservation and restoration" ("Norme AES portant sur les métadonnées audio - structures des objets audio pour la conservation et la restauration" (en anglais (NDT)) codifient cet aspect de la question.
3.7.2 Des registres de format sont disponibles aujourd'hui, bien qu'encore en développement, pour faciliter la catégorisation et la validation des formats de fichiers dans les tâches de pré-chargement : PRONOM (registre technique en ligne, comprend les formats de fichiers, maintenu par TNA (The National Archives, UK), qui peut être utilisé conjointement avec un autre outils de TNA, DROID (Digital Record Object Identification (Identification d'enregistrement numérique d'objets) - qui effectue l'identification automatique de lots de formats de fichiers et de sorties de métadonnées). En provenance des Etats-Unis, Université de Harvard, les outils GDFR (Global Digital Format Registry) (Registre de format numérique global) et JHOVE (JSTOR/Harvard Object Validation Environment identification, validation, and characterization of digital object) (identification de l'environnement, validation et caractérisation des objets numériques) offrent des services comparables permettant la conservation des compilations de métadonnées. Une information précise des formats de fichiers est essentielle pour atteindre l'objectif de conservation à long terme.
3.7.3 Le plus important concerne les aspects de conservation et de transfert relatifs aux fichiers audio, y compris la totalité des paramètres techniques, qui doivent être soigneusement évalués et préservés. Ce qui implique l'ensemble des mesures qui doivent être prises pour assurer la sauvegarde des documents audio tout le long de leur vie. Même si de nombreuses métadonnées discutées ici peuvent être ajoutées sans encombre à une date postérieure, l'enregistrement de la création du fichier audionumérique (et tout changement apporté à son contenu) doit être créé au moment où se produit l'événement. Cet historique des métadonnées permet de suivre l'intégrité de l'item audio et, si l'on utilise le format BWF, elles peuvent être enregistrées en tant que partie intégrante du fichier par codage de l'historique dans le bloc BEXT. Cette information constitue une partie essentielle des recommandations formulées à l'adresse des métadonnées de conservation PREMIS. L'expérience montre que les systèmes informatiques sont en mesure de produire d'abondantes données techniques lors du processus de numérisation. Des données qu'il faudra peut-être distiller dans les métadonnées qui doivent être conservées. Des ensembles d'éléments utiles sont proposés dans la série provisoire AudioMD (http://www.loc.gov/rr/mopic/avprot/audioMD_v8.xsd), un schéma d'extension développé par la Library of Congress (Bibliothèque du Congrès), ou bien par le schéma de l'AES audio Object XML qui, au moment d'écrire ces lignes est en révision pour normalisation.
3.7.4 Dans le cas de la numérisation de collections légales, ces schémas sont utiles, non seulement pour décrire les fichiers numériques, mais également pour décrire l'original physique. Des précautions doivent prises afin d'éviter toute ambiguïté à propos des objets en cours de description dans les métadonnées : il devient nécessaire de décrire les tâches, leurs manifestations originales, les versions numériques subséquentes, mais la capacité de pouvoir distinguer ce qui est décrit dans chaque instance revêt une importance critique. PREMIS réalise la distinction des différentes composantes dans la séquence de changement en les associant avec les événements et en reliant les métadonnées résultantes au cours du temps.
3.8 Métadonnées structurelles - METS
3.8.1 Les médias temporels, très fréquemment de type audiovisuels, sont complexes. Un enregistrement in situ peut être constitué d'une séquence d'événements (sons, danses, rituels) accompagné d'images et de notes de terrain. Un long entretien historique occupant plus d'un fichier .wav peut aussi être accompagné de photographies des intervenants, de transcriptions ou d'analyses linguistiques. Les métadonnées structurelles dressent un inventaire de tous les fichiers pertinents et intelligents des relations externes et internes en y incluant les séquençages préférés ; par exemple les actes et les scènes d'un enregistrement d'opéra. La norme METS (Metadata Encoding and Transmission Standard : Norme de codage et de transmission des métadonnées) version actuelle 1.11, qui comporte des sections « carte de structure » (structMap) et « groupe de fichiers » (fileGrp) peut faire valoir un bilan positif avéré des applications dans le contexte de l'audiovisuel (voir fig. 3)
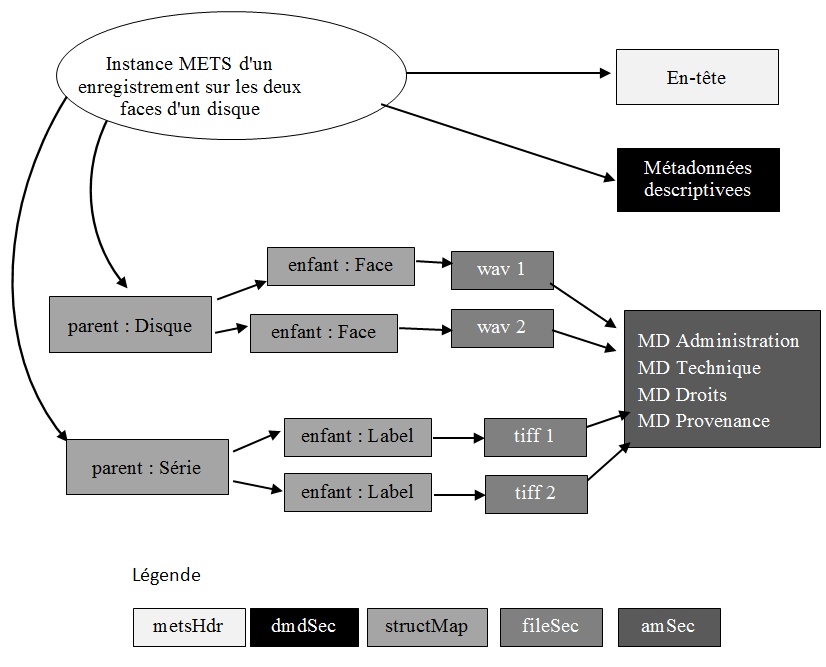
Fig. 3 : composantes d'une instance METS avec un jeu possible de relations entre-elles
3.8.2 Composantes d'une instance METS :
3.8.2.1 L'en-tête décrit l'objet METS, celui qui l'a créé, quand, et dans quel but. L'information consignée dans l'en-tête participe à la gestion du fichier METS correspondant.
3.8.2.2 La section des métadonnées descriptives contient l'information décrivant la ressource représentée par l'objet original, ce qui permet de la découvrir.
3.8.2.3 La carte de structure, représentée par les feuillets individuels et les détails, dans l'ordre des fichiers numériques de l'objet disposés selon une hiérarchie dans laquelle on peut naviguer.
3.8.2.4 La section des fichiers de contenu, représentée par des images, une sur cinq, déclare quels fichiers numériques constituent l'objet. Les fichiers peuvent être soit intégrés à l'objet, soit référencés.
3.8.2.5 La section des métadonnées administratives contient des informations sur les fichiers numériques déclarés dans la section des fichiers de contenu. Cette section se subdivise en :
3.8.2.5.1 Métadonnées techniques, définit les caractéristiques techniques d'un fichier
3.8.2.5.2 Métadonnées source, précise la source de la capture (par exemple, capture directe ou reformatée avec transparence 4x5)
3.8.2.5.3 Métadonnées de provenance numérique, précise quelles modifications ont été appliquées sur un fichier depuis sa naissance
3.8.2.5.4 Métadonnées portant sur les droits, précise les conditions légales d'accès
3.8.2.6 Les différentes sections des métadonnées techniques, des métadonnées sources, et des métadonnées de provenance numérique fournissant les informations pertinentes de la conservation numérique.
3.8.2.7 Pour satisfaire la complétude, la section comportement, non présentée dans la Fig. 2 ci-dessus, associe des exécutables avec un objet METS. Exemple, un objet METS peut s'appuyer sur une certaine partie du code pour créer une instance à des fins de visualisation, la section comportement pouvant référencer ce code.
3.8.3 Il peut être nécessaire de représenter des objets métiers en supplément des métadonnées de structure.
3.8.3.1 Information d'utilisateur (authentification)
3.8.3.2 Droits et licences (manière d'utiliser un objet)
3.8.3.3 Politiques (manière dont un objet a été sélectionné par les archives)
3.8.3.4 Services (acquittement des copies et des droits)
3.8.3.5 Organisations (collaborations, partie prenantes, sources de financement)
3.8.4 Ces éléments peuvent être représentés par des fichiers référencés à une adresse spécifique ou URL. Des annotations explicatives peuvent être fournies dans les métadonnées pour les lectures humaines.
3.9 Métadonnées descriptives – Profils d'application, Dublin Core (DC)
3.9.1 Une grande partie des efforts consacrés aux métadonnées dans le domaine patrimonial ont mis l'accent sur les métadonnées descriptives en tant que ramification du catalogage traditionnel. Toutefois, il est clair qu'une attention excessive dans ce domaine (par exemple raffinement localisé des balises descriptives et vocabulaires contrôlés) aux dépens d'autres considérations décrites ci-dessus provoquera des défauts dans le système. La Fig. 4 met en évidence les diverses interdépendances qu'il convient de mettre en place, ainsi que les balises de métadonnées descriptives qui constituent en quelque sorte un sous-ensemble de tous les éléments en jeu.
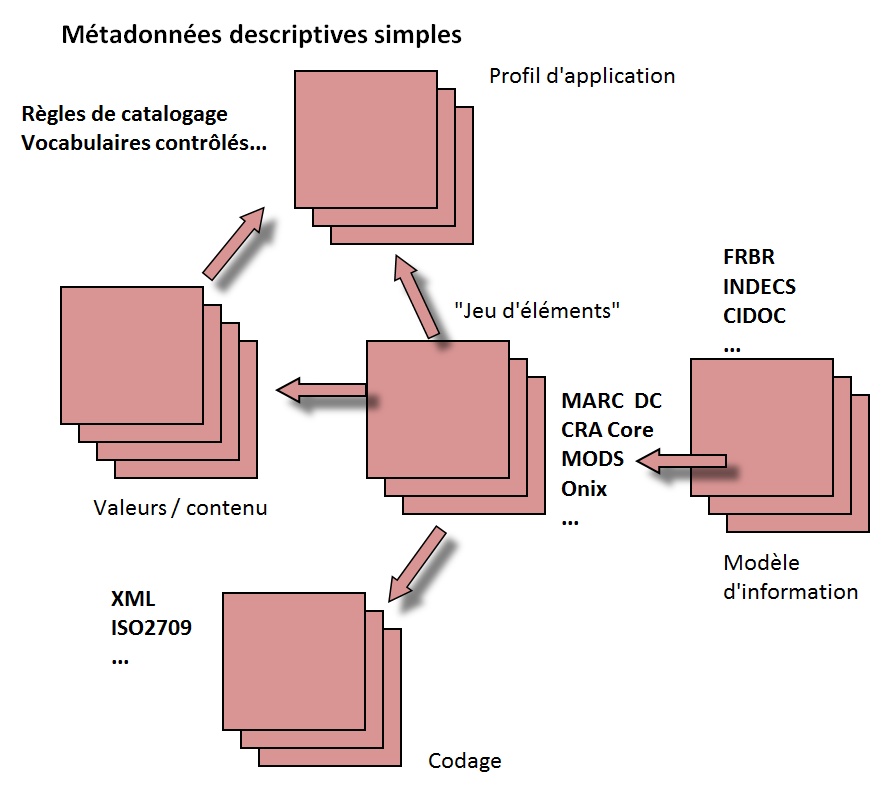
Fig. 4 : Métadonnées descriptives simples (Avec l'autorisation de Dempsey, CLIR/DLF primer, 2005)
3.9.2 L'interopérabilité doit être une composante essentielle de toute stratégie concernant les métadonnées : pour un entrepôt d'archives, la conception par une équipe dédiée de systèmes élaborés et indépendants les uns des autres conduira à une faible productivité, des coûts élevés et une portée minimum. Il en résultera une industrie artisanale de métadonnées incapable de se développer. Les métadonnées descriptives illustrent en effet le cas classique de la maxime de Richard Gabriel 'Worse is better' ('Moins bien, c'est mieux). Comparant deux programmes de langage, l'un élégant mais complexe, l'autre maladroit mais simple, Gabriel prédit avec raison que le langage le plus simple se développera plus rapidement, et qu'ainsi, davantage de personnes seraient amenées à améliorer le langage simple plutôt que le langage complexe. La démonstration d'un tel cas de figure est apportée par la manière dont s'est généralisé le succès de Dublin Core (DC), pourtant considéré initialement par les professionnels comme une solution improbable du fait de sa très grande simplicité.
3.9.3 La mission de DCMI (DC Metadata Initiative) a consisté à favoriser la détection des ressources sur internet. Ceci grâce au développement de standards de métadonnées permettant de repérer les ressources dans différents domaines, grâce à la définition de structures assurant l'interopérabilité de sets (regroupements) de métadonnées, et enfin grâce au développement de sets spécifiques d'une communauté ou d'une discipline qui soient en cohérence avec leurs objectifs. Un vocabulaire de quinze éléments seulement est utilisé pour la description des ressources, pour l'ensemble des trois catégories de métadonnées. Aucun élément n'est obligatoire : tous sont reproductibles, même si les intégrateurs peuvent spécifier d'autres profils d'application - voir paragraphe 3.9.8 ci-dessous. L'origine du nom "Dublin" provient de la ville de l'Ohio qui a accueilli en 1995 le groupe de travail ; "core" (cœur) provient du fait que les éléments, de portée générale, génériques, sont utilisables pour décrire un large éventail de ressources. L'utilisation de DC s'est répandue durant plus d'une décennie, les quinze éléments descriptifs ayant été officiellement adoptés dans les normes suivantes : ISO Standard 15836-2003 de février 2003 (février 2009) [ISO 15836 http://dublincore.org/documents/dces/#ISO15836 ] (2009) NISO standard Z39.2007 de Mai 2007 [NISOZ3985 http://dublincore.org/documents/dces/#NIZO3985 ] et IETF RFC 5014 d'Août 2007 [RFC5013 http://dublincore.org/documents/dces/#RFC5013 ].
Tableau 1 (ci-dessous) listes des quinze éléments DC avec leurs définitions officielles (abrégé) et suggestions d'interprétation dans un contexte audiovisuel.
| Eléments DC | Définition DC | Interprétation audiovisuelle |
|---|---|---|
| Title (Titre) | Nom donné à la ressource | Titre principal associé à l'enregistrement |
| Subject (Sujet) | Sujet de la ressource | Principaux thèmes couverts |
| Description (Description) | Présentation de la ressource | Notes explicatives, résumés d'entretiens, descriptions du contexte environnemental ou culturel, liste des contenus |
| Creator (Créateur) | Entité principalement responsable de la réalisation de la ressource | Ni l'auteur, ni le compositeur des œuvres enregistrées mais le nom du service d'archivage |
| Publisher (Editeur) | Entité responsable de la mise à disposition de la ressource | N'est pas l'éditeur du document original numérisé. Typiquement l'éditeur et le créateur sont les mêmes |
| Contributor (Contributeur) | Entité responsable des contributions au contenu de la ressource | Toute personne ou source sonore citée. Nécessite des qualificatifs appropriés tels que le rôle joué (par ex. interprète, personne qui a effectué l'enregistrement) |
| Date (Date) | Moment ou période associée à un événement du cycle de vie de la ressource | N'est pas la date d'enregistrement ou de l'original (P) mais une date relative à la ressource elle-même |
| Type (Type) | Nature ou genre du contenu de la ressource | Domaine de la ressource, non le genre musical. Ainsi Son : oui, Jazz : non |
| Format (Format) | Format de fichier, medium physique, ou dimensions de la ressource | Format de fichier, non du support physique original |
| Identifier (Identifiant) | Référence non ambigüe de la ressource dans un contexte donné | Susceptible d'être l'URI du fichier audio |
| Source (Source) | Ressource apparentée dont la ressource décrite est dérivée | Référence à une ressource dont la ressource présente est dérivée |
| Language (Langue) | Langue de la ressource | Langue de la ressource |
| Relation (Relation) | Ressource apparentée | Référence aux objets apparentés |
| Coverage (Couverture) | Périmètre spatio-temporel de la ressource, domaine spatial d'application de la ressource ou juridiction compétente en vertu de laquelle la ressource est pertinente. | Ce qu'illustre l'enregistrement, par exemple des particularismes culturels tels que des chants traditionnels ou un dialecte |
| Rights (Gestion des droits) | Information sur les droits associés à la ressource | Information sur les titulaires de droits associés à la ressource |
Tableau 1 : Les 15 éléments DC
3.9.4 Afin d'inclure des propriétés supplémentaires dans le processus, le nombre d'éléments de DC a été augmenté. Ainsi, un certain nombre d'éléments ajoutés ("termes") serviront à décrire les média basés sur le temps :
| Termes DC | Définition DC | Interprétation audiovisuelle |
|---|---|---|
| Alternative (Alternatif) | Toute forme de titre utilisée comme substitut ou alternative du titre formel de la ressource | Titre alternatif, par ex. un titre traduit, un pseudonyme, un rangement alternatif d'éléments dans un titre générique |
| Extent (Etendue) | Taille ou durée de la ressource | Taille et durée d'un titre |
| Extent Original (Etendue d'origine) | Manifestation physique ou numérique de la ressource | Taille ou durée de l'enregistrement de la source d'origine |
| Spatial (Spatial) | Caractéristiques spatiales du contenu intellectuel de la ressource | Localisation de l'enregistrement comprenant les coordonnées topographiques compatibles avec les interfaces cartographiques |
| Temporal (Temporel) | Caractéristiques temporelles du contenu intellectuel de la ressource | Circonstances dans lesquelles l'enregistrement a été effectué |
| Created (Créé) | Date de création de la ressource | Date d'enregistrement et toute autre date importante dans le cycle de vie de l'enregistrement |
Tableau 2 Termes (sélection)
3.9.5 Les intégrateurs de DC peuvent faire le choix d'utiliser les quinze éléments soit dans leur ancien dc: variant (par exemple, http://purl.org/dc/elements/1.1/creator) ou dans le dcterms: variant (par exemple, http://purl.org/dc/terms/creator) en fonction des exigences d'applications. Toutefois, au fil du temps, en particulier si RDF fait partie de la stratégie des métadonnées, on s'attend (avec les encouragements de la DCMI) à ce que les intégrateurs utilisent la sémantique plus précise dcterms: properties, ils se conformeront strictement aux bonnes pratiques des métadonnées destinées aux machines de traitement.
3.9.6 Y compris sous cette forme étendue, la granularité de DC peut être insuffisante pour répondre aux exigences d'archives audiovisuelles spécialisées. L'élément Contributor, par exemple, nécessitera la mention du rôle du contributeur dans l'enregistrement pour éviter, dans ce cas de figure, la confusion entre interprètes et compositeurs ou acteurs et auteurs. Une liste de rôles communs (ou 'relators') ('rapporteurs') a été élaborée pour des agents (MARC relators) par la Library of Congress. Voici deux exemples de la manière dont ils peuvent être implémentés.
<dcterms:contributor> <marcrel:CMP>Beethoven,Ludwig van, 1770-1827</marcrel:CMP> <marcrel:PRF>Quatuor Pascal</marcrel:PRF> </dcterms:contributor> <dcterms:contributor> <marcrel:SPK>Greer,Germaine, 1939- (female)</marcrel:SPK> <marcrel:SPK>McCulloch, Joseph, 1908-1990 (male)</marcrel:SPK> </dcterms:contributor>
Le premier exemple place une balise 'Beethoven' en tant que compositeur (composer) (CMP) et 'Quatuor Pascal' en tant qu'interprète (performer) (PRF). La deuxième balise place les deux contributeurs, Greer et McCulloch en tant que locuteurs (speakers) (SPK) sans aller jusqu'à déterminer celui qui mène l'interview et celui qui répond aux questions. Cette information devrait être transmise à un autre endroit dans les métadonnées, par exemple dans Description ou Title.
3.9.7 A cet égard, un schéma différent peut-être préférable, ou pourrait être inséré en tant que schéma d'extension supplémentaire (illustration dans la Fig. 2). MODS (Metadata Object Description Schema http://www.loc.gov/standards/mods/) permet, par exemple, d'obtenir une granularité plus importante des noms et des liens avec les fichiers d'autorité, reflet de sa filiation avec la norme MARC :
name
Subelements
namePart
Attribute: type (date, family, given, termsOfAddress)
displayForm
affiliation
role
roleTerm
Attributes: type (code, text); authority
(voir:www.loc.gov/marc/sourcecode/relator/relatorsource.html)
description
Attributes: ID; xlink; lang; xml:lang; script; transliteration
type (enumerated: personal, corporate, conference)
authority
(voir:www.loc.gov/marc/sourcecode/authorityfile/authorityfilesource.html)
3.9.8 En utilisant METS, il serait possible d'inclure plus d'un lot (set) de métadonnées descriptives adaptées en vue d'objectifs différents, par exemple un lot Dublin Core (en conformité avec OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting)) et un lot MODS plus sophistiqué adapté à d'autres initiatives, notamment l'échange de fiches codées avec des systèmes MARC. Cette possibilité d'inclure d'autres approches standards constitue l'un des avantages de METS.
3.9.9 DC, sous la gouvernance de la Dublin Core Metadata Initiative (DCMI) poursuit son développement. D'une part, son efficacité pour la mise en réseau des ressources est renforcée par l'association accrue d'outils sémantiques du web tels que RDF (voir Nilsson et al, DCMI 2008) tandis que, d'autre part, il vise à accroître sa pertinence dans le domaine patrimonial en l'associant de manière formelle avec les recommandations RDA (Resource Description & Access http://www.collectionscanada.gc.ca/jsc/rda.html) [nom de domaine remplacé par http://www.rda-jsc.org/rda.html en 2009]. Si RDA est considéré comme un successeur opportun des règles de catalogage anglo-américaines, ce développement particulier peut conduire à des implications dans les archives audiovisuelles qui font partie des bibliothèques nationales et universitaires. En ce qui concerne les archives de la radiodiffusion, d'autres développements basés sur DCMI ont atteint une certaine notoriété. Au moment de rédiger ce document, l'EBU (European Broadcast Union) UER (Union Européenne de Radiodiffusion) complète le développement du jeu de métadonnées EBU Core Metadata Set, tiré de Dublin Core et compatible avec lui.
3.9.10 Le service d'archives peut souhaiter modifier (développer, adapter) l'ensemble des éléments de base (core). De tels ensembles modifiés s'appuyant sur un ou plusieurs schémas d'espace de nom (namespace) existant (MODS et/ou IEEE LOM aussi bien que DC par exemple) sont connus sous le nom de profils d'applications. Tous les éléments d'un profil d'application proviennent de l'extérieur, de schémas d'espaces de noms distincts. Si des programmeurs souhaitent créer de 'nouveaux' éléments non schématisés par ailleurs, par exemple lorsque des rôles de contributeurs d'instance ne sont pas disponibles dans le jeu MARC relators (agents non humains ou autres espèces, machines, environnements), ils doivent créer leur propres schémas d'espaces de noms, et prendre leur responsabilité en 'déclarant' et maintenant ce schéma.
3.9.11 Les profils d'application comprennent une liste d'espaces de noms qui assurent l'administration en même temps que les URL courants (de préférence PURL - URL permanents). Ceux-ci sont recopiés dans chaque instance de métadonnées. Il en résulte une liste de chacun des éléments de données comportant à la fois les valeurs permises et le style de contenu. Elles peuvent faire référence à des règles internes ou additionnelles et à des vocabulaires contrôlés, par exemple des thésaurus de noms et genres d'instruments, des fiches d'autorité de noms personnels et de sujets. Le profil spécifiera aussi les schémas obligatoires d'éléments particuliers telles les dates (AAAA-MM-JJ) et les coordonnées géographiques, de telles représentations standards de localisation et du temps pourront contribuer à l'affichage cartographique et temporel en tant que dispositif de récupération non-textuelle.
| Nom ou Terme | Titre |
|---|---|
| Term URI (Terme URI) | http://purl.org/dc/elements/1.1/title |
| Label (Label) | Titre |
| Defined by (Défini par) | http://dublincore.org/documents/dcmi-terms/ |
| Source Definition(Définition de la Source) | Nom donné à une ressource |
| BLAPS-S Definition (Définition BLAPS-S) | Titre de l'œuvre ou composante de l'œuvre |
| Source Comments (Commentaires sur la source) | Typiquement, un titre est le nom par lequel la source est formellement connue |
| BLAPS-S Definition (Commentaires BLAPS-S) | Si aucun titre n'est disponible il convient d'en donner un à partir de la ressource ou fourni [sans titre]. On suivra les pratiques de catalogage normales pour les titres d'enregistrement dans d'autres langues utilisant un raffinement 'Alternatif'. Pour les données issues du catalogue d'archives sonores, cela revient à donner l'un des domaines de titres suivants dans l'ordre hiérarchique tel que : Titre de l'œuvre (1), Titre de l'item (2), Titre de la collection (3), Titre de du produit (4), Espèces originales (5), Titre de radiodiffusion (6), Titre Séries éditées (7), séries non éditées (8) |
| Type of term (Type de terme) | Elément |
| Refines (Raffinements) | |
| Refined by (Raffiné par) | Alternative |
| Has encoding schemes (Schéma encodé par) | |
| Obligation (Obligation) | Obligatoire |
| Occurrence (Occurence) | Non répétable |
Fig. 5 : Partie du profil d'application du DC de la British Library pour le son (BLAP-S) :
Espaces de noms utilisés dans ce profil d'application
Termes de métadonnées DCMI : http://dublincore.org/documents/dcmi-terms/
RDF http://www.w3.org/RDF/
Eléments MODS http://www.loc.gov/mods
Termes TEL http://www.theeuropeanlibrary.org/metadatahandbook/telterms.htm
Termes BL http://www.bl.uk/schemas/bibliographic/blterms
MARCREL http://www.loc.gov/loc.terms/relators/
3.9.12 En conséquence, le profil d'application s'incorpore ou s'appuie sur un dictionnaire de données (fichier définissant l'organisation élémentaire de la base de données jusqu'aux champs individuels et types de champs), ou bien sur plusieurs dictionnaires de données, ainsi la maintenance peut-elle être assurée par un seul centre d'archives ou de manière partagée avec une communauté d'archives. Le dictionnaire de données PREMIS (http://www.loc.gov/standards/premis/v3/premis-3-0-final.pdf, version 3 actuellement) se rapportant exclusivement à la conservation, est susceptible d'être utilisé de manière conséquente. Ses nombreux éléments sont dénommés 'Unités sémantiques'. Les métadonnées de conservation fournissent des renseignements sur la provenance, l'activité de conservation, les caractéristiques techniques, et facilitent la vérification de l'authenticité d'un objet numérique. Le PREMIS Working Group a publié son dictionnaire Data Dictionary for Preservation Metadata en Juin 2005, il recommande de l'utiliser dans tous les entrepôts de conservation quel que soit le type de matériau archivé et quelles que soient les stratégies de conservation employées.
3.9.13 En définissant les profils d'application et, plus important, en les déclarant, les programmeurs peuvent partager l'information à propos de leurs schémas afin de collaborer, à grande échelle, à des tâches universelles telle que celle de la conservation à long terme.
3.10 Sources de métadonnées
3.10.1 Les services d'archivage ne doivent pas s'attendre à créer elles même toutes les métadonnées descriptives en partant de zéro (l'ancienne manière). Etant donnée l’imbrication des ressources et des métadonnées tout au long de leur vie, une telle notion est en fait inopérante. Pour réduire les coûts et apporter un enrichissement par l'extension des entrées, plusieurs sources de métadonnées sont à considérer, notamment la catégorie des métadonnées descriptives. On compte trois sources principales : professionnelle, contributive et intentionnelle : elles peuvent être déployées parallèlement.
3.10.2 Les sources professionnelles, cela signifie qu'elles sont élaborées sur la valeur intangible des bases de données légales, des fichiers d'autorité et des vocabulaires contrôlés valables pour les matériels publiés ou dupliqués. Les bases de données industrielles tout autant que les catalogues d'archives sont concernés. De telles sources, en particulier les catalogues d'archives, sont notoirement incomplets et incapables d'interopérations sans la mise en œuvre de programmes de conversion sophistiqués et de protocoles complexes. Il y a presque autant de standards de données opérationnels dans les industries d'enregistrement et de radiodiffusion ou dans le domaine du patrimoine audiovisuel qu'il y a de bases de données séparées. Le manque de solution universelle pour l'AV, telle que l'ISBN pour l'imprimé, est un obstacle permanent et après des décennies d'efforts en matière discographique, il reste encore des divergences sur ce qui constitue une notice de catalogage : une piste individuelle ou une séquence de pistes réalise-t-elle une unité intellectuelle telle qu'une œuvre musicale constituée de multiples sections ou une œuvre littéraire ? Est-ce-la somme totale des pistes d'un simple support ou d'un ensemble de supports ? En d'autres termes, le support physique est-il l'unité de catalogage ? Manifestement, un organisme qui choisit une définition de plus grande granularité trouvera qu'il est plus facile de réussir l'export de ses données légales dans une infrastructure de métadonnées. Les approches "ceinture et bretelles" de l'export des données tirées de Z39.50 (http://www.loc.gov/z3950/agency/protocol for information retrieval) et SRW/SU (un protocole de recherche et de récupération via les URL standards avec réponse XML standard) permettent d'atteindre un certain niveau de réussite, de même que la capacité des ordinateurs à moissonner les métadonnées à partir des ressources centralisées. Cependant, il faudrait investir de manière plus efficace dans la production partagée des ressources d’identification et de description des noms, des sujets, des emplacements, des périodes et les œuvres.
3.10.3 Par sources contributives il faut comprendre les contenus générés par les utilisateurs. Ces dernières années, un phénomène important s'est manifesté par l'émergence de nombreux sites qui sollicitent, regroupent et exploitent les données contributives des utilisateurs, et qui mobilisent ces données pour classer, recommander et commenter les ressources. Ceci inclus, par exemple, YouTube et LastFM. Ces sites ont une certaine utilité en ce qu'ils révèlent les relations entre personnes, entre personnes et ressources et entre les informations portant sur les ressources elles-mêmes. Les bibliothèques ont commencé à expérimenter ces approches ; il y a de vrais avantages à tirer par le fait que les utilisateurs peuvent accroître le nombre de métadonnées en provenance de sources professionnelles. Les caractéristiques du soi-disant Web 2.0 qui supporte les contributions et les syndications des utilisateurs, sont devenues de banals systèmes de gestion de contenus disponibles.
3.10.4 Intentionnelle signifie que les données collectées sur des utilisations et des usages peuvent améliorer la découverte des ressources. Le concept est emprunté au secteur commercial comme les recommandations d'Amazon, basées sur des choix d'achats groupés. Des algorithmes similaires peuvent être utilisés pour classer des objets dans une ressource. Ce type de données est apparu comme un facteur central des sites web à succès, procurant des chemins utiles à travers des volumes intidimidantes d'informations complexes.
3.11 Nécessité de futurs développements
3.11.1 Dans le contexte des travaux et développements récents, les métadonnées restent une science immature, même si ce chapitre démontre qu'un nombre important de blocs substantiels en construction (dictionnaires de données, schémas, ontologies et codages) étaient maintenant en place pour commencer à répondre à l'appétit des chercheurs qui souhaitent accéder plus facilement aux contenus AV, et répondre à l'ambition tenace de notre profession de sauvegarder leur persistance. Pour accélérer les progrès, il sera nécessaire de trouver des terrains communs entre secteurs publiques et commerciaux, et entre les différentes catégories d'archives audiovisuelles, chacune d'entres-elles ayant élaboré ses propres outils et standards.
3.11.2 Un certain succès a été obtenu avec la dérivation automatique des métadonnées des ressources. Nous avons besoin d'en faire plus, car les processus manuels existant notamment ne s'adaptent pas bien. Par ailleurs, la production de métadonnées ne semble pas acceptable à moins de mieux rentabiliser le processus. "Nous ne devons pas alourdir les dépenses et la complexité, ce qui est la tendance quand les développements passent par de multiples canaux faisant consensus et qui répondent aux impératifs d'une partie seulement de l'environnement de service" (Dempsey : 2005).
3.11.3 Le problème de la réconciliation des bases de données, c'est-à-dire la capacité d'un système à comprendre que les items sont sémantiquement identiques bien qu'ils puissent être représentés de différentes manières, reste une question ouverte. Des recherches significatives ont été entreprises pour résoudre ce problème, mais une solution appropriée générale reste à trouver. Cette question est également très importante pour la gestion de la persistance dans OAIS comme le démontre l'exemple suivant. L'expression sémantique indiquant que Wolfgand Amadeus Mozart est le compositeur de la plupart des pièces du Requiem (K. 626) est présentée de manière totalement différente dans le modèle FRBR en comparaison d'une liste de simples relevés DCMI. Pour DCMI, 'Compositeur' est un raffinement de 'contributeur' et 'Mozart' est sa propriété; tandis que dans le modèle FRBR, compositeur est une relation entre une personne physique et un opus. L'utilisation de vocabulaires contrôlés est aussi une manière de s'assurer que W.A. Mozart représente bien la même personne, Mozart.